python
-
[Python] BackgroundTasks, Celery 2024.09.06
-
 [Python] 코루틴 사용법 1 2024.01.26
[Python] 코루틴 사용법 1 2024.01.26 -
 [FastAPI] SocketIO Admin UI 2024.01.25
[FastAPI] SocketIO Admin UI 2024.01.25 -
 [FastAPI] room 기능 구현 및 worker간 공유 (RabbitMQ) 2024.01.24
[FastAPI] room 기능 구현 및 worker간 공유 (RabbitMQ) 2024.01.24 -
 [FastAPI] SocketIO 마운트해서 사용하기 2024.01.24
[FastAPI] SocketIO 마운트해서 사용하기 2024.01.24 -
[FastAPI] BackgroundTasks, Celery 2024.01.09
-
[Python] lock 사용법 2023.10.04
-
 [Streamlit] Streamlit 사용법 2023.06.07
[Streamlit] Streamlit 사용법 2023.06.07
[Python] BackgroundTasks, Celery
FastAPI 내에서
BackgroundTasks와 Celery 사용에 대해 알아보자.
하나의 물리적 서버(또는 컨테이너)에서 실행되는 경우
모든 프로세스는 같은 물리적 메모리를 공유한다.
하지만 운영 체제 수준에서 각 프로세스에 할당되는 가상 메모리는 서로 독립적이다.
BackgroundTasks
- FastAPI 애플리케이션은 자체 프로세스 메모리를 갖는다.
- BackgroundTasks는 FastAPI worker 프로세스의 메모리를 직접 사용한다.
(FastAPI worker 프로세스 내에서 실행되기 때문에 FastAPI 애플리케이션과 동일한 메모리 공간을 공유)
따라서
작업이 많아지거나 무거워지면 FastAPI 애플리케이션이 과부화될 수 있다.
이는 메모리 사용량이 높아져 worker가 다운되는 상황이 발생할 수 있다.
간단하고 빠른 작업에 적합하여
메모리 집약적인 작업은 FastAPI worker를 불안정하게 만들 수 있다.
ex) 이메일 전송, 간단한 데이터 처리 등
Celery
FastAPI처럼 분리된 서비스라기보다는 백그라운드 작업을 처리하기 위한 도구로,
FastAPI 내부에서 사용할 수 있거나 별도의 작업 처리 서버(worker)로 동작할 수 있다.
컨테이너를 따로 띄워서 운영할 수 있지만, 운영 방식일 뿐
Celery 자체는 Python 애플리케이션에서 동작하는 라이브러리이다.
- Celery worker는 별도의 프로세스로 실행된다.
- FastAPI 애플리케이션과 독립적인 메모리 공간을 갖는다.
따라서 FastAPI 애플리케이션의 메모리가 가득 차더라도 Celery worker는 영향을 받지 않고 계속 실행 될 수 있다.
다만, 컨테이너의 전체 메모리가 소진되면 컨테이너 자체가 불안정해질 수 있다.
- 복잡하고 메모리 집약적인 작업에 적합
ex) 대용량 데이터 처리, 머신러닝 모델 훈련 등
Celery를 사용할 때는 보통 Redis나 RabbitMQ와 같은 message broker도 함께 실행해야 한다.
이 broker는 FastAPI와 Celery 사이의 통신을 관리한다.
Celery는 작업을 큐에 넣고 worker들이 그 큐에서 작업을 가져가서 처리하는 역할은 한다.
즉, Celery 자체는 작업을 관리하고 처리하는 역할을 하지만
작업이 큐에 쌓이는 것을 조절하는 기능을 제공하지 않는다.
이 때, Lock 통해 요청을 적절히 제한하는 것이 필요하다
Lock을 걸어주는 이유는,
이미 Celery worker가 어떤 작업을 수행 중일 때 동일한 작업을 중복해서 실행하지 않도록 방지하기 위함이다.
Redis 등을 통해 특정 작업이 이미 처리 중인지를 확인하고
Lock이 걸려 있다면 새로운 작업을 요청하지 않는 방식으로 구현할 수 있다.
주의할 점은
Redis에서 KEYS * 또는 KEYS all 같은 명령어를 사용하면 모든 키를 검색할 수 있다.
Redis는 키-값 저장소로서 매우 빠르지만, 위와 같은 명령어는 성능에 큰 영향을 줄 수 있다.
Redis가 단일 스레드로 동작하기 때문에 KEYS 명령어를 실행하는 동안
Redis 서버는 해당 명령을 처리하기 위해 모든 키를 순회하게 되고
이 과정에서 Redis의 다른 작업들이 일시적으로 멈추거나 느려질 수 있다.
이로 인해 다른 클라이언트의 요청이 지연되거나 차단될 수 있다.
- 단일 프로세스
Celery worker 자체는 단일 프로세스로 동작한다.
- 다중 프로세스
하지만 여러 Celery worker를 실행하면 여러 개의 프로세스가 생성되고
각 worker는 개별적으로 작업을 병렬로 처리하므로, 여러 작업을 동시에 처리할 수 있다.
- 멀티프로세싱
멀티프로세싱은 하나의 프로세스 안에서 서브 프로세스를 추가로 생성해 병렬로 작업을 처리하는 방식을 말한다.
Celery 자체적으로는 worker 하위에 멀티프로세싱을 지원하지 않는다.
하지만 특정 작업에서 멀티프로세싱이 필요하다면,
Celery worker 안에 직접 서브 프로세스를 만들어서 처리하는 방식을 사용할 수 있다.
- 코루틴
Celery worker 내에서 코루틴을 사용하여 단일 프로세스 내에서 여러 작업을 동시에 처리할 수 있다.
| Multiprocessing | Coroutine | |
| 작업 처리 방식 | 다중 프로세스, 병렬 처리 | 단일 프로세스, 비동기 동시성 처리 |
| CPU 활용 | 다중 CPU 코어 사용 가능 | 단일 CPU 코어만 사용 |
| 적합한 작업 유형 | CPU 바운드 작업 (대규모 계산 등) | I/O 바운드 작업 (네트워크, 파일 입출력) |
| 메모리 사용 | 프로세스마다 메모리 독립 | 메모리 공유, 상대적으로 적음 |
| 성능 | CPU 집약적인 작업에서 더 좋음 | 대규모 I/O 작업에서 효율적 |
| 복잡도 | 프로세스 간 통신 필요, 복잡도가 높음 | 단일 프로세스에서 작동, 상대적으로 단순 |
작업 유형에 따라 적합한 동시성 처리 방식을 사용하면 된다.
Celery는 다양한 concurrency 옵션을 제공하여 다양한 유형의 작업을 효율적으로 처리할 수 있게 한다.
- Prefork Pool (기본)
여러 개의 worker 프로세스를 미리 생성
CPU-bound 작업에 적합
ex) celery -A app worker --concurrency=4
- Eventlet
단일 프로세스 내에서 여러 작업을 동시에 처리
그린 스레드 기반의 비동기 처리
I/O bound 작업에 적합
ex) celery -A app worker --pool=eventlet --concurrency=100
- Gevent
Eventlet과 유사한 그린 스레드 기반 처리
I/O bound 작업에 적합
ex) celery -A app worker --pool=gevent --concurrency=100
- Solo Pool
단일 프로세스로 동작
디버깅이나 특정 상황에서 유용
ex) celery -A app worker --pool=solo
? 그린스레드 (Green Threads) ?
OS 스레드 (운영체제가 관리하는 실제 하드웨어 스레드)와는 다르게,
사용자 레벨에서 관리되는 경량 스레드이다.
OS가 스레드를 스케줄링하는 대신, Python 인터프리터 내에서 스레드 스케줄링이 이루어진다.
| Green Threads (Eventlet, Gevent) | Coroutine (async/await) | |
| 실행 방식 | 여러 '가상 스레드'가 단일 OS 스레드 내에서 번갈아 실행됨 | 명시적인 async/await 구문을 통해 작업을 적환 |
| 동시성 관리 주체 | 라이브러리(Eventlet, Gevent) 내부에서 자동 처리 | 사용자 코드에서 명시적으로 제어 |
| 작업 전환 | 비동기 작업이 발생하면 그린 스레드 간에 자동 전환 | await 시 다른 비동기 함수로 전환 |
| 작업 대상 | 주로 I/O 바운드 작업 | 주로 I/O 바운드 작업 |
| 성능 | 더 많은 컨텍스트 전환을 처리할 수 있으나, 코루틴보다 약간의 오버헤드가 있음 |
비교적 가볍고 더 명시적임 |
| 적용 범위 | Eventlet, Gevent가 설치된 환경에서만 동작 | 표준 Python 3.5+에서 지원 |
그린 스레드는 하나의 OS 스레드 내에서 실행된다.
즉, 실제로는 단일 OS 스레드가 작업을 수행하지만 이 안에서 그린 스레드들이 교대로 실행된다.
여러 그린 스레드가 돌아가는 것처럼 보이지만 실제로는 하나의 OS 스레드가 전환하면서 처리하고 있는 것이다.
이 전환은 비동기 작업(예: I/O 대기)시 자동으로 이루어진다.
Python 자체가 각 그린 스레드의 실행을 관리하는 것이고
각 그린 스레드가 I/O 대시 상태에 있을 때 다른 그린 스레드가 CPU를 차지하여 작업을 이어서 수행한다.
반면 코루틴은 함수 수준에서 비동기 코드를 작성한다.
여기서 '함수 수준'이라는 말은 코루틴이 특정 함수 단위로 전환될 수 있다는 것을 의미한다.
코루틴에서 async 함수는 CPU-bound 작업을 하지 않고,
특정 시점에서 명시적으로 await을 통해 다른 작업으로 전환된다.
프로그래머가 언제, 어떤 작업을 대기 상태로 만들고, 다른 작업을 재개할지 직접 제어하는 것이 코루틴의 핵심이다.
즉, 코루틴은 작업이 실행될 때 직접 전환을 요청해야 하는 반면,
그린 스레드는 OS 스레드처럼 자동으로 전환된다.
코루틴은 함수가 비동기 작업을 만났을 때만 명시적으로 다른 작업으로 넘어가고,
그린 스레드는 I/O 대기 시 자동으로 다른 작업으로 전환되는 방식이다.
# Gevent 예시
import gevent
from gevent import monkey; monkey.patch_all()
import time
def task1():
print("Task 1 start")
time.sleep(1) # Gevent가 자동으로 전환
print("Task 1 end")
def task2():
print("Task 2 start")
time.sleep(1)
print("Task 2 end")
gevent.joinall([gevent.spawn(task1), gevent.spawn(task2)])# 코루틴 예시
import asyncio
async def task1():
print("Task 1 start")
await asyncio.sleep(1) # 명시적으로 await을 통해 전환
print("Task 1 end")
async def task2():
print("Task 2 start")
await asyncio.sleep(1)
print("Task 2 end")
async def main():
await asyncio.gather(task1(), task2())
asyncio.run(main())'Python > 파이썬 고급' 카테고리의 다른 글
| [Python] lock 사용법 (0) | 2023.10.04 |
|---|
[Python] 코루틴 사용법
asyncio.run()
이 함수는 외부에서 호출되며,
코루틴을 실행하기 위한 새로운 이벤트 루프를 생성하고, 코루틴이 완료될 때까지 이벤트 루프를 실행한 후 종료
기본적으로 프로그램의 진입점에서 한 번 사용
asyncio.create_task()
이벤트 루프 내에서 비동기적으로 실행할 코루틴을 task로 스케쥴링
이렇게 생성된 task는 즉시 이벤트 루프에 의해 실행되며 task의 완료를 기다리지 않고 다음 줄의 코드가 실행됨
await
코루틴 실행을 일시 중단하고, 해당 코루틴이 완료될 때까지 현재 코루틴의 실행을 중지
완료되면, await 다음의 코드가 실행됨
비동기 작업이 완료될 때까지 기다려야 할 경우에 사용
ex) 특정 데이터를 받아와야 다음 단계의 코드를 실행할 수 있는 경우
await는 비동기 작업의 완료를 기다리지만, 전통적인 blocking 방식과는 다름
블록킹 방식에서는 작업이 완료될 때까지 프로그램의 실행히 완전히 멈춤
반면, 비동기 방식에서는 await으로 특정 작업의 완료를 기다리는 동안 이벤트 루프가 다른 비동기 작업을 수행할 수 있게 해줌
완료를 기다리지만 다른 작업을 수행할 수 있게 한다?
이해가 잘 안된다.
예시를 보자.
1. await을 만난 비동기 작업 A는 I/O 작업 등으로 인해 완료를 기다려야 한다.
2. 이벤트 루프는 작업 A가 완료될 때까지 대기하고 있을 동안, 다른 준비된 비동기 작업 B를 실행한다.
3. 작업 B도 await을 만나면, 이벤트 루프는 다시 다른 준비된 작업(ex: 작업 C)으로 전환할 수 있다.
4. 이 과정을 통해, 이벤트 루프는 실행 가능한 비동기 작업을 계속 찾아 실행하며, 각 작업의 대기 시간을 효율적으로 활용한다.
결국, await으로 인해 기다려야 하는 특정 작업이 있더라도, 프로그램 전체가 멈추는 것이 아니라,
가능한 다른 작업들을 계속해서 처리할 수 있다.
이것이 바로 비동기 프로그래밍이 제공하는 동시성의 이점이다!
import asyncio
import datetime
async def my_task(num, second):
start_time = datetime.datetime.now()
print(f"Task {num} 시작")
await asyncio.sleep(second) # second초 후에 작업이 완료됩니다.
end_time = datetime.datetime.now()
print(f"Task {num} 완료")
return end_time - start_time
async def main():
start_time = datetime.datetime.now()
# my_task를 태스크로 스케줄링합니다.
# 태스크는 즉시 이벤트 루프에 의해 실행되지만, main()의 흐름은 여기서 멈추지 않습니다.
task1 = asyncio.create_task(my_task(1, 2))
# 이 시점에서 main()의 다음 줄로 바로 넘어갑니다. 태스크의 완료를 기다리지 않습니다.
print("main()의 다음 코드 실행")
task2 = asyncio.create_task(my_task(2, 5))
# 그러나 여기서 await을 사용하여 태스크의 완료를 기다립니다.
duration1 = await task1
duration2 = await task2
end_time = datetime.datetime.now()
print(f"Task 1 소요 시간: {duration1}")
print(f"Task 2 소요 시간: {duration2}")
print(f"main 함수의 전체 실행 시간: {end_time - start_time}")
# 이벤트 루프를 시작하고 main() 코루틴을 실행합니다.
asyncio.run(main())
전체 실행 시간이 7초가 아닌 5초로 단축됐다.
asyncio.Future()
비동기 작업의 결과를 나타내는데 사용되는 객체
아직 완료되지 않은 작업을 추적하고, 해당 작업이 완료되면 결과를 저장, 이후 결과 조회 가능
* Future 객체의 주요 메서드 *
cancel() : Future의 작업 취소, 작업이 이미 완료되었거나 취소되었다면 효과 없음
cancelled() : Future의 작업이 취소되었는지 여부 반환
done() : Future의 작업이 완료되었는지 여부 반환
result() : Future의 결과 반환, Future가 아직 완료되지 않았다면, 호출자를 block
set_result() : Future의 결과를 설정, Future가 완료되었음을 알리며, result() 호출에 의해 반환될 값 설정
asyncio.gather()
주어진 코루틴이나 Future 객체들을 동시에 실행하고, 모든 결과를 하나의 리스트로 반환
gather로 실행 중인 코루틴이라 Future 객체들이 독립적을 실행되고,
서로의 완료를 기다리지는 않음
import asyncio
async def worker(future):
print('Worker: Starting work')
await asyncio.sleep(1)
print('Worker: Done with work')
future.set_result('Worker result')
async def boss(future):
print('Boss: Waiting for worker to finish')
result = await future
print(f'Boss: Received result: {result}')
async def main():
future = asyncio.Future()
await asyncio.gather(boss(future), worker(future))
asyncio.run(main())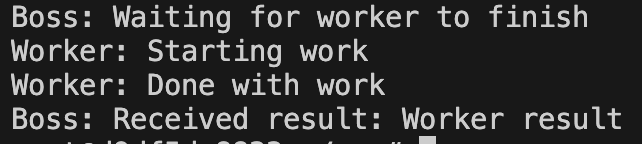
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 어노테이션(annotation), typing (0) | 2023.04.10 |
|---|---|
| [Python] 코루틴 (Coroutine) (0) | 2023.02.16 |
| [Python] 이터레이터(iterator), 제너레이터(generator) (0) | 2022.12.14 |
| [Python] setdefault 함수 (0) | 2022.12.11 |
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
[FastAPI] SocketIO Admin UI
Socket.IO의 admin UI는 Socket.IO 서버의 상태를 실시간으로 모니터링할 수 있는 대시보드다.
실시간 통계
현재 연결된 클라이언트 수, 수신 및 전송된 이벤트 수, 데이터 트래픽 등의 통계
로그 뷰어
서버의 로그를 실시간으로 확인
이벤트 테스터
서버로 이벤트를 보내거나, 서버로부터 이벤트를 받는 것을 시뮬레이션
룸 뷰어
서버에 현재 존재하는 room과 그 방에 연결된 클라이언트 확인
인증
보안을 위한 인증 기능
인증된 사용자만이 Admin UI에 접근
# sockets.py
mgr = socketio.AsyncAioPikaManager('amqp://guest:guest@rabbitmq:5672/vhost')
sio_server = socketio.AsyncServer(
async_mode = 'asgi',
cors_allowed_origins=[
'http://localhost:8000/ws',
'https://admin.socket.io'
],
client_manager=mgr
)
sio_server.instrument(auth={
'username': 'admin',
'password': 'admin',
})
sio_app = socketio.ASGIApp(
socketio_server=sio_server,
socketio_path='/ws/socket.io'
)
서버 설정에 admin을 추가한 후
https://admin.socket.io로 접속하면 된다.

설정에 맞게 접속하면 된다.

'WebFramework > [FastAPI]' 카테고리의 다른 글
| [FastAPI] Gunicorn threads 옵션 (0) | 2024.11.06 |
|---|---|
| [FastAPI] room 기능 구현 및 worker간 공유 (RabbitMQ) (0) | 2024.01.24 |
| [FastAPI] SocketIO 마운트해서 사용하기 (0) | 2024.01.24 |
| [FastAPI] BackgroundTasks, Celery (0) | 2024.01.09 |
| [FastAPI] 중첩된 JSON 모델(Nested JSON Models) 사용 (0) | 2023.09.25 |
[FastAPI] room 기능 구현 및 worker간 공유 (RabbitMQ)
room 기능을 구현해보자.
이전 글과 server.py는 변한게 없다.
# sockets.py
import socketio
sio_server = socketio.AsyncServer(
async_mode = 'asgi',
cors_allowed_origins=[]
)
sio_app = socketio.ASGIApp(
socketio_server=sio_server,
socketio_path='/ws/socket.io'
)
@sio_server.on('connect')
async def connect(sid, environ, auth):
print(f'{sid}: connected')
@sio_server.on('enter_room')
async def begin_chat(sid, room):
print(f'{sid}: enterd "{room}"')
await sio_server.enter_room(sid, room)
@sio_server.on('exit_room')
async def exit_chat(sid, room):
await sio_server.leave_room(sid, room)
@sio_server.on('disconnect')
async def disconnect(sid):
print(f'{sid}: disconnected')# client.py
import socketio
import asyncio
sio_client = socketio.AsyncClient()
@sio_client.event
async def connect():
print('I\'m connected')
await sio_client.emit('enter_room', 'my_room')
@sio_client.event
async def disconnect():
print('I\'m disconnected')
async def main():
await sio_client.connect(
url='http://localhost:8000/ws',
socketio_path='/ws/socket.io'
)
await sio_client.disconnect()
asyncio.run(main())터미널 세션 두 개를 열어 client를 두 명 만들어보자


FastAPI log를 확인해보면 sid가 다른 두 명의 클라이언트가 my_room 이라는 방에 들어왔다가 나간걸 확인할 수 있다.
클라이언트가 정말 같은 방에 있는지 확인하기 위해
서버에서 my_room에 있는 클라이언트들에게 메시지를 보내보자.
# socket.py
@sio_server.on('chat_message')
async def chat_message(sid, data):
message = data['message']
room = data['room']
print(f'{sid} in [{room}]: {message}')
await sio_server.emit('server_response', message, room=room)# client.py
@sio_client.event
async def connect():
print('I\'m connected')
await sio_client.emit('enter_room', 'my_room')
await sio_client.emit('chat_message', {'room': 'my_room', 'message': 'I\'m in "my_room"!'})
@sio_client.event
async def server_response(data):
print('Server response:', data)
async def main():
await sio_client.connect(
url='http://localhost:8000/ws',
socketio_path='/ws/socket.io'
)
await asyncio.sleep(30)
await sio_client.disconnect()
서버에서 메시지를 보내는 로직을 추가하고
client 두 명을 테스트하기 위해 30초 sleep 또한 추가했다.

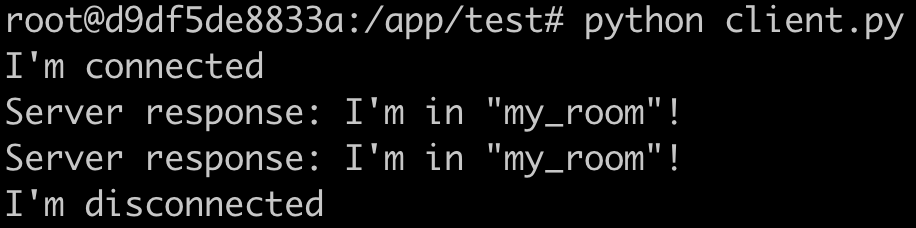

두 번째 client를 실행했을 때 첫 번째 client에 I'm in "my_room"!이 한 번 더 출력됨을 확인할 수 있다.
이렇게 원하는 room을 만들고 접속하여 room 안에 client들이 통신할 수 있다.
지금까지는
uvicorn server:app --host 0.0.0.0 --port 8000 --reload 처럼 FastAPI의 worker가 하나였다.
worker가 여러 개 띄우고 결과를 보자.
gunicorn -k uvicorn.workers.UvicornWorker -w 5 -b 0.0.0.0:8000 server:app --reload
gunicorn을 사용해 worker를 5개 띄우고 client 2개를 실행해보자.



첫 번째 실행한 client에 두 번째 client의 출력이 뜨지 않았다.
이유는 각각 독립적으로 실행되기 때문이다.
FastAPI의 워커를 여러 개 띄우면 각 워커는 고유한 프로세스로 실행된다.
이는 각 프로세스가 자체 메모리 공간을 가지고 독립적으로 실행된다는 것을 의미한다.
따라서, 각각의 워커는 고유한 Socket.IO 서버 인스턴스를 가지며, 트래픽은 운영체제에 의해 랜덤하게 워커로 할당된다.
이 인스턴스들은 서로의 상태를 공유하지 않는다.
이를 해결하기 위해 여러 워커 간의 상태를 공유할 수 있는 방법이 필요하다.
Socket.IO에는 이러한 환경을 위해 외부 메시지 브로커를 사용하는 방법이 있다.
메시지 브로커를 사용해 다른 워커/프로세스 간에 메시지를 중계할 수 있으며
이를 통해 모든 클라이언트가 동일한 my_room에 있는 것처럼 동작하게 할 수 있다.
외부 메시지 브로커로는 RabbitMQ를 사용하려고 한다.
# sockets.py
mgr = socketio.AsyncAioPikaManager('amqp://guest:guest@rabbitmq:5672/vhost')
sio_server = socketio.AsyncServer(
async_mode = 'asgi',
cors_allowed_origins=[],
client_manager=mgr
)
aio-pika를 설치한 후
manager를 추가해주면 끝이다.
마찬가지로 worker를 5개 띄우고 client를 2개 띄워 RMQ와 함께 확인해보자.



첫 번째 실행한 client 출력에 두 번째 client의 출력이 보인다.
client 별로 FastAPI에서 처리되는 worker가 다르더라도 같은 my_room에서 메시지가 오고가고 있다.
Rabbit MQ 웹을 확인해보자.
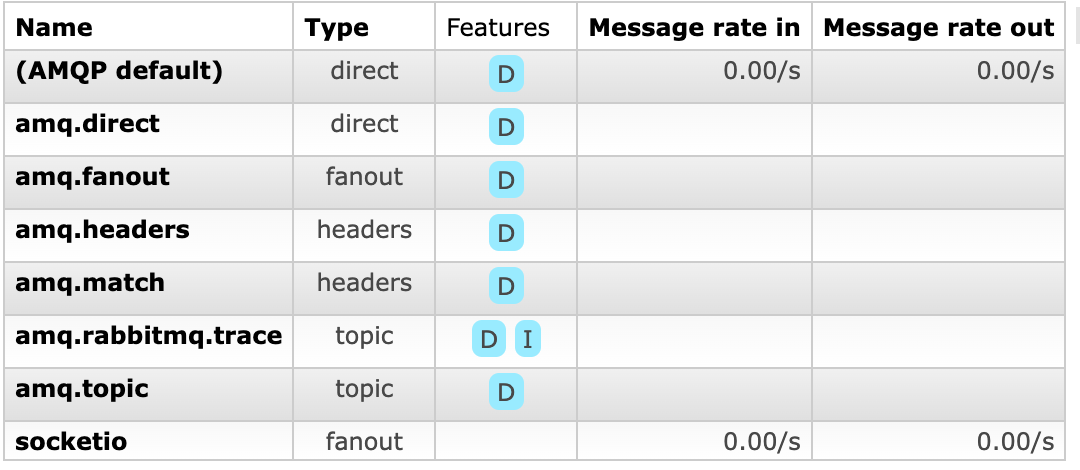
socketio exchange가 생겼다.
이를 통해 room에 있는 client 모두에게 서버 메시지를 전송할 수 있는 것이다.
'WebFramework > [FastAPI]' 카테고리의 다른 글
| [FastAPI] Gunicorn threads 옵션 (0) | 2024.11.06 |
|---|---|
| [FastAPI] SocketIO Admin UI (0) | 2024.01.25 |
| [FastAPI] SocketIO 마운트해서 사용하기 (0) | 2024.01.24 |
| [FastAPI] BackgroundTasks, Celery (0) | 2024.01.09 |
| [FastAPI] 중첩된 JSON 모델(Nested JSON Models) 사용 (0) | 2023.09.25 |
[FastAPI] SocketIO 마운트해서 사용하기
"사용자 2명 : 챗봇" 을 구현하기 위해
room 기능을 제공하는 SocketIO를 사용하기로 했다.
SocketIO는 WebSocket을 기반으로 하는 라이브러리지만
WebSocket에만 의존하지 않고 필요한 경우 다른 전송 방법 (ex_폴링)을 사용할 수 있다.
또한 WebSocket보다 고급 기능을 제공한다.
챗봇 엔진은 FastAPI를 사용하기로 했다.
따라서 SocketIO를 FastAPI에 mount해서 사용해야 한다.
# sockets.py
import socketio
sio_server = socketio.AsyncServer(
async_mode = 'asgi',
cors_allowed_origins=[]
)
sio_app = socketio.ASGIApp(
socketio_server=sio_server,
socketio_path='/ws/socket.io'
)
@sio_server.on('connect')
async def connect(sid, environ, auth):
print(f'{sid}: connected')
@sio_server.on('disconnect')
async def disconnect(sid):
print(f'{sid}: disconnected')# server.py
from fastapi import FastAPI
from sockets import sio_app
app = FastAPI()
@app.get('/')
async def home():
return {'message': 'Hello World'}
app.mount('/ws', app=sio_app)
FastAPI에서 mount는 특정 경로에 외부 WSGI 또는 ASGI 애플리케이션을 연결하는 기능을 의미한다.
즉, FastAPI 애플리케이션의 일부 경로를 외부 애플리케이션에 위임하는 것이다.
이를 통해 FastAPI 애플리케이션에서는 HTTP 요청을 처리하고
특정 경로에서는 외부 애플리케이션이 요청을 처리하도록할 수 있다.
위 코드는
모든 '/ws'로 시작하는 경로에 대한 WebSocket 요청을 외부 애플리케이션인 'sio_app'에 위임하여 처리하는 것이다.
여기서 주의할 점은 경로 설정이다.
SocketIO 앱 (socketio.ASGIApp)을 마운트할 때 사용하는 경로에 따라서 클라이언트에서 연결을 시도하는 경로가 달라질 수 있다.
app.mount('/ws', socketio.ASGIApp(sio))를 사용하면 클라이언트는 /ws/socket.io 경로로 연결 해야한다.
socketio.ASGIApp의 기본 socketio_path가 'socket.io'이기 때문이다.
참고로 python-socketio 라이브러리에서
@sio.on('event_name')와 @sio.event는 동일한 기능이다.
두 가지 방식으로 이벤트 핸들러를 등록할 수 있으며
단지, @sio.on('event_name')방식은 이벤트 이름을 명시적으로 지정하는 반면
@sio.event방식은 핸들러 함수의 이름을 이벤트 이름으로 사용한다.


테스트를 위해 Postman을 사용했지만 제대로 동작하지 않았다.
문서에서 제공하는 python-socketio[asyncio_client]를 사용해 클라이언트를 생성했다.
# client.py
import socketio
import asyncio
sio_client = socketio.AsyncClient()
@sio_client.event
async def connect():
print('I\'m connected')
@sio_client.event
async def disconnect():
print('I\'m disconnected')
async def main():
await sio_client.connect(
url='http://localhost:8000/ws',
socketio_path='/ws/socket.io'
)
await sio_client.disconnect()
asyncio.run(main())
FastAPI를 실행하자
uvicorn server:app --host 0.0.0.0 --port 8000 --reload
이후 client를 실행하면 아래와 같다.


다음 글은 room 기능 구현!
'WebFramework > [FastAPI]' 카테고리의 다른 글
| [FastAPI] SocketIO Admin UI (0) | 2024.01.25 |
|---|---|
| [FastAPI] room 기능 구현 및 worker간 공유 (RabbitMQ) (0) | 2024.01.24 |
| [FastAPI] BackgroundTasks, Celery (0) | 2024.01.09 |
| [FastAPI] 중첩된 JSON 모델(Nested JSON Models) 사용 (0) | 2023.09.25 |
| [FastAPI] SQLAlchemy 요소 (0) | 2023.08.08 |
[FastAPI] BackgroundTasks, Celery
BackgroundTasks
사용자가 데이터를 요청하고, 서버가 이 데이터를 처리하는 데 시간이 걸리는 경우,
서버는 먼저 HTTP 응답을 반환하고, 그 후에 백그라운드에서 데이터 처리를 계속할 수 있다.
이렇게 하면 사용자는 서버의 응답을 빠르게 받을 수 있다.
예시 코드를 보자.
from fastapi import BackgroundTasks, FastAPI
app = FastAPI()
def write_log(message: str):
with open("log.txt", "a") as file:
file.write(message)
@app.post("/send/{message}")
async def send_message(background_tasks: BackgroundTasks, message: str):
background_tasks.add_task(write_log, message)
return {"message": "Message received"}FastAPI는 본질적으로 비동기 프레임워크다.
Starlette(비동기 웹 프레임워크) 위에 구축되어 있으며,
따라서 Python의 async와 await 키워드를 사용하여 동시에 여러 요청을 처리할 수 있다.
FastAPI의 BackgroundTasks는 각 작업을 별도의 스레드에서 실행한다.
즉, BackgroundTasks.add_task() 메소드에 전달된 함수는 메인 스레드(=HTTP 요청을 처리하는 스레드)와는
별도의 스레드에서 실행된다.
이렇게 하면, 메인 스레드는 블로킹되지 않고(=I/O작업이 완료되기를 기다리지 않고) 다른 요청을 계속 처리할 수 있다.
하지만
복잡한 계산이나 작업을 수행하는 경우 동일한 프로세스의 일부로 실행하지 않는 것이 좋다.
따라서 이러한 복잡한 작업을 별도의 프로세스로 수행하려면 celery를 사용하면 된다.
celery
파이썬에서 사용하는 비동기 작업 큐/작업 스케줄링 시스템이다.
메시지 브로커를 통해 메시지를 전달하고, 작업자(worker) 프로세스가 이 메시지(일반적으로 작업 또는 태스크)를 가져와서 처리한다.
- 시간이 오래 걸리는 작업을 백그라운드에서 처리해야 할 때
- 많은 양의 작업을 병렬로 처리해야 할 때
- 정기적으로 반복되는 작업을 스케줄링해야 할 때
주요 구성 요소
- Producer: 작업을 만들고 메시지 브로커에 전송하는 파트입니다. 일반적으로 웹 애플리케이션에서 요청을 처리하는 동안 작업을 생성하고 큐에 넣습니다.
- Broker: 작업 메시지를 큐에 보관하고, 작업자에게 전달하는 중개자 역할을 합니다. RabbitMQ, Redis 등 다양한 메시지 브로커를 사용할 수 있습니다.
- Worker: 실제로 작업을 처리하는 프로세스입니다. 브로커로부터 작업 메시지를 받아 처리하고 결과를 저장합니다.
- Backend: 작업의 결과를 저장하는 곳입니다. 이는 선택 사항이며, 작업의 결과를 추적하거나, 작업이 성공적으로 완료되었는지 확인하려는 경우에 사용됩니다.
celery는 이런 구조를 통해 큰 규모의 분산 작업 처리를 가능하게 한다.
병렬 처리, 작업 우선 순위, 스케줄링 등 다양한 기능을 제공하며
신뢰성있는 작업 처리를 위한 실패 시 재시도, 작업 결과 추적 등의 기능도 제공하다.
FasAPI, Celery, RMQ 예제
https://medium.com/cuddle-ai/async-architecture-with-fastapi-celery-and-rabbitmq-c7d029030377
Async Architecture with FastAPI, Celery, and RabbitMQ
In one of my earlier tutorials, we have seen how we can optimize the performance of a FastAPI application using Async IO. To know more you…
medium.com
BackgroundTask와 Celery는 모두 비동기 작업을 처리하는 데 사용되지만
차이점은 아래와 같다.
BackgroundTasks
동일한 프로세스 내에서 별도의 스레드에서 실행되며, 작업이 완료 될 때까지 메인 스레드의 실행을 차단하지 않는다.
그러나 Python의 Global Interpreter Lock(GIL) 때문에
CPU-bound 작업에서는 이 방식이 큰 성능 향상을 가져오지 못할 수 있다.
Celery
별도의 작업자(worker) 프로세스에서 비동기 작업을 처리하는데 사용된다.
이는 메시지 브로커를 통해 메인 애플리케이션과 작업자 프로세스 간에 작업을 전달한다.
따라서 복잡하거나 시간이 오래 걸리는 작업, 또는 대량의 작업을 병렬로 처리하는데 적합하다.
또한 각 작업자 프로세스는 독립적으로 실행되므로, GIL에 의한 제한을 받지 않는다.
결국 BackgroundTasks는 간단하고 빠른 작업에 적합하고,
Celery는 복잡하거나 오래 걸리는 작업에 적합하다.
'WebFramework > [FastAPI]' 카테고리의 다른 글
| [FastAPI] room 기능 구현 및 worker간 공유 (RabbitMQ) (0) | 2024.01.24 |
|---|---|
| [FastAPI] SocketIO 마운트해서 사용하기 (0) | 2024.01.24 |
| [FastAPI] 중첩된 JSON 모델(Nested JSON Models) 사용 (0) | 2023.09.25 |
| [FastAPI] SQLAlchemy 요소 (0) | 2023.08.08 |
| [wsl] 파이썬 가상환경 진입 bash 사용 (0) | 2023.03.10 |
[Python] lock 사용법
.lock 파일
파일 락(lock)을 관리하고 다른 프로세스 또는 스레드와의 충돌을 방지하기 위해 사용되는 파일
일반적으로 어떤 프로세스가 파일을 사용하고 있는지 나타내는 역할
파일을 쓰고 있는 동안 다른 프로세스나 스레드가 해당 파일을 동시에 수정하려고 할 때 충돌이 발생하는 것을 방지
파일 접근제어
.lock 파일이 있는 경우
이 파일을 소유한 프로세스만 해당 파일을 수정할 수 있으며,
다른 프로세스는 접근을 시도할 때 대기하거나 충볼을 방지하기 위한 작업을 수행
파일 락 해제
파일 작업이 완료되면 해당 파일의 락(lock)을 해제
이는 다른 프로세스나 스레드가 해당 파일을 수정할 수 있도록 허용하는 역할
동기화
.lock 파일은 데이터베이스 파일 또는 다른 공유 리소스에 대한 동기화에 사용될 수 있음
락 걸기 (Locking)
파일을 락으로 설정하여 다른 프로세스 또는 스레드의 접근을 제한
주로 사용되는 락 함수로는 fcntl(파일 컨트롤) 또는 flock(파일 락)과 같은 POSIX 표준 라이브러리가 있음
프로세스 간 동기화를 위해 뮤텍스(Mutex)나 세마포어(Semaphore)와 같은 동기화 기법을 사용할 수 있음
import fcntl
file = open("example.txt", "w")
# 파일 락 걸기
fcntl.flock(file.fileno(), fcntl.LOCK_EX)
# 파일을 안전하게 수정 가능
# 파일 락 해제
fcntl.flock(file.fileno(), fcntl.LOCK_UN)
file.close()락 해제 (Unlocking)
파일 락을 해제하여 다른 프로세스나 스레드의 접근을 허용
fcntl 이나 flock을 사용하여 파일 락을 걸었다면, 해당 라이브러리 함수를 호출하여 락을 해제
뮤텍스나 세마포어를 사용한 경우,
해당 뮤텍스나 세마포어의 해제 함수를 호출하여 다른 프로세스에게 리소스를 반환
import fcntl
file = open("example.txt", "w")
# 파일 락 해제
fcntl.flock(file.fileno(), fcntl.LOCK_UN)
file.close()
파일 락을 제대로 사용하지 않으면 데이터 무결성 문제가 발생할 수 있으므로 주의 필요
'Python > 파이썬 고급' 카테고리의 다른 글
| [Python] BackgroundTasks, Celery (0) | 2024.09.06 |
|---|
[Streamlit] Streamlit 사용법
Streamlit이란?
파이썬 기반의 오픈 소스 라이브러리
사용자가 작성한 파이썬 코드를 자동으로 웹 애플리케이션으로 변환해주는 기능 제공
데이터 시각화, 대시보드, 머신러닝 모델의 결과 시각화, 데이터 분석 도구 등 다양한 분야에서 사용 가능
공식 문서 : https://docs.streamlit.io/library/get-started
Streamlit 설치
pip install streamlit이후 아래 명령어로 Streamlit 데모 페이지를 볼 수 있다.
기본 8501port를 사용한다.
streamlit hello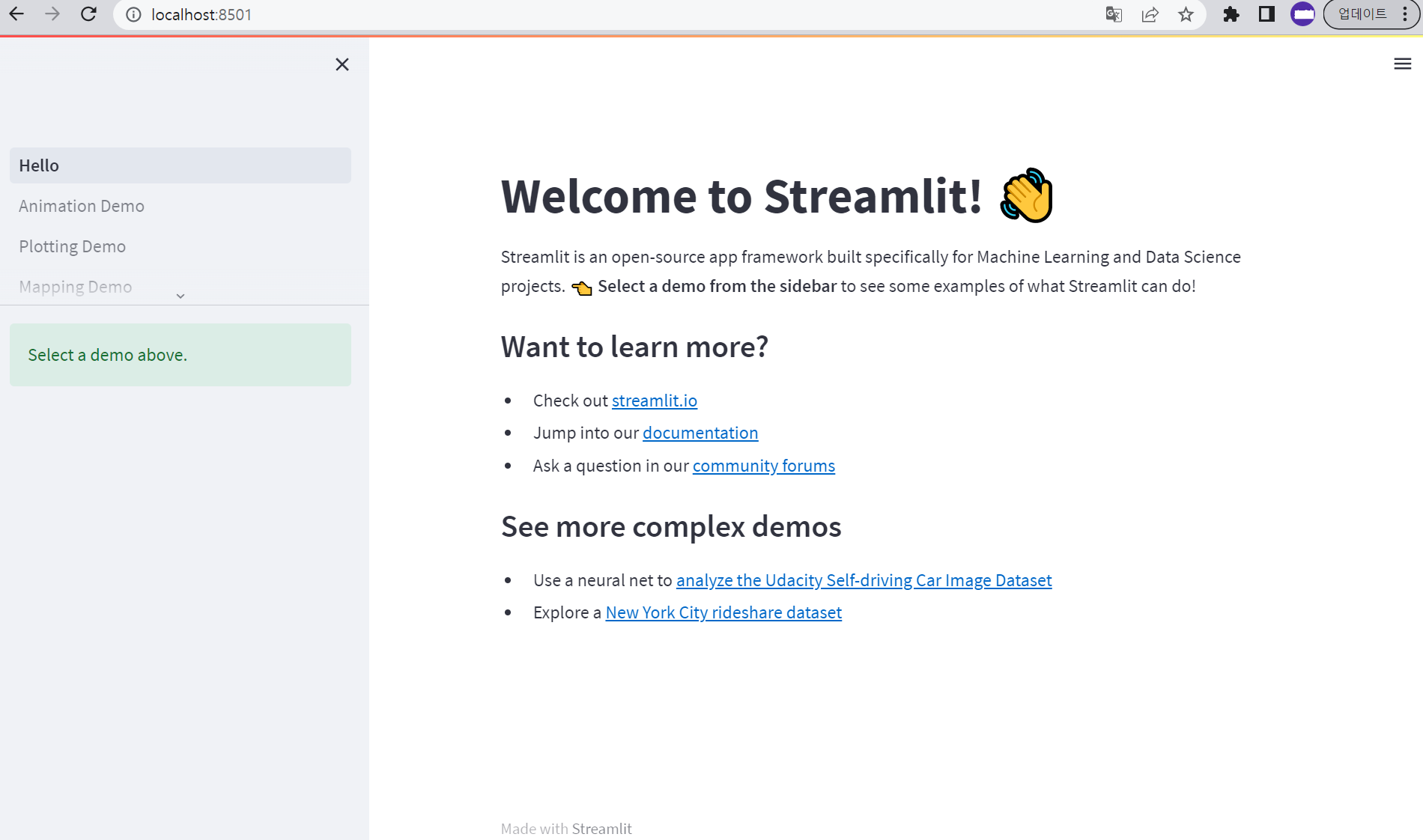
예시코드
웹 페이지에 "Hello Word"를 출력해보자.
# stTest.py
import streamlit as st
st.write('Hello World')앱에 인수를 쓰기 위해 write()를 사용한다.
이후 아래 명령어로 해당 파일을 실행하게 되면 local streamlit 서버가 가동된다.
streamlit run stTest.py
# 또는
python -m streamlit run stTest.py
파이썬 파일을 수정하고 저장하면 웹에 아래와 같은 info가 나오고 Always rerun을 선택하면
자동으로 앱 변경을 감지하고 실시간으로 반영된다.

인수 출력 외에도 다양한 기능이 있다.


추가적인 기능은 공식문서를 참고하면 된다.
공식문서가 잘 되어 있다!