Python
-
[Python] BackgroundTasks, Celery 2024.09.06
-
 [Python] 코루틴 사용법 1 2024.01.26
[Python] 코루틴 사용법 1 2024.01.26 -
[Python] lock 사용법 2023.10.04
-
[Python] 파이썬 실행 과정 (Python Compile) 2023.06.01
-
[Python] 구현한 모듈 import하기 2023.05.23
-
[Python] vars() 2023.05.22
-
[Python] VO, DTO, DAO 2023.05.22
-
[Python] strftime과 strptime 2023.05.22
[Python] BackgroundTasks, Celery
FastAPI 내에서
BackgroundTasks와 Celery 사용에 대해 알아보자.
하나의 물리적 서버(또는 컨테이너)에서 실행되는 경우
모든 프로세스는 같은 물리적 메모리를 공유한다.
하지만 운영 체제 수준에서 각 프로세스에 할당되는 가상 메모리는 서로 독립적이다.
BackgroundTasks
- FastAPI 애플리케이션은 자체 프로세스 메모리를 갖는다.
- BackgroundTasks는 FastAPI worker 프로세스의 메모리를 직접 사용한다.
(FastAPI worker 프로세스 내에서 실행되기 때문에 FastAPI 애플리케이션과 동일한 메모리 공간을 공유)
따라서
작업이 많아지거나 무거워지면 FastAPI 애플리케이션이 과부화될 수 있다.
이는 메모리 사용량이 높아져 worker가 다운되는 상황이 발생할 수 있다.
간단하고 빠른 작업에 적합하여
메모리 집약적인 작업은 FastAPI worker를 불안정하게 만들 수 있다.
ex) 이메일 전송, 간단한 데이터 처리 등
Celery
FastAPI처럼 분리된 서비스라기보다는 백그라운드 작업을 처리하기 위한 도구로,
FastAPI 내부에서 사용할 수 있거나 별도의 작업 처리 서버(worker)로 동작할 수 있다.
컨테이너를 따로 띄워서 운영할 수 있지만, 운영 방식일 뿐
Celery 자체는 Python 애플리케이션에서 동작하는 라이브러리이다.
- Celery worker는 별도의 프로세스로 실행된다.
- FastAPI 애플리케이션과 독립적인 메모리 공간을 갖는다.
따라서 FastAPI 애플리케이션의 메모리가 가득 차더라도 Celery worker는 영향을 받지 않고 계속 실행 될 수 있다.
다만, 컨테이너의 전체 메모리가 소진되면 컨테이너 자체가 불안정해질 수 있다.
- 복잡하고 메모리 집약적인 작업에 적합
ex) 대용량 데이터 처리, 머신러닝 모델 훈련 등
Celery를 사용할 때는 보통 Redis나 RabbitMQ와 같은 message broker도 함께 실행해야 한다.
이 broker는 FastAPI와 Celery 사이의 통신을 관리한다.
Celery는 작업을 큐에 넣고 worker들이 그 큐에서 작업을 가져가서 처리하는 역할은 한다.
즉, Celery 자체는 작업을 관리하고 처리하는 역할을 하지만
작업이 큐에 쌓이는 것을 조절하는 기능을 제공하지 않는다.
이 때, Lock 통해 요청을 적절히 제한하는 것이 필요하다
Lock을 걸어주는 이유는,
이미 Celery worker가 어떤 작업을 수행 중일 때 동일한 작업을 중복해서 실행하지 않도록 방지하기 위함이다.
Redis 등을 통해 특정 작업이 이미 처리 중인지를 확인하고
Lock이 걸려 있다면 새로운 작업을 요청하지 않는 방식으로 구현할 수 있다.
주의할 점은
Redis에서 KEYS * 또는 KEYS all 같은 명령어를 사용하면 모든 키를 검색할 수 있다.
Redis는 키-값 저장소로서 매우 빠르지만, 위와 같은 명령어는 성능에 큰 영향을 줄 수 있다.
Redis가 단일 스레드로 동작하기 때문에 KEYS 명령어를 실행하는 동안
Redis 서버는 해당 명령을 처리하기 위해 모든 키를 순회하게 되고
이 과정에서 Redis의 다른 작업들이 일시적으로 멈추거나 느려질 수 있다.
이로 인해 다른 클라이언트의 요청이 지연되거나 차단될 수 있다.
- 단일 프로세스
Celery worker 자체는 단일 프로세스로 동작한다.
- 다중 프로세스
하지만 여러 Celery worker를 실행하면 여러 개의 프로세스가 생성되고
각 worker는 개별적으로 작업을 병렬로 처리하므로, 여러 작업을 동시에 처리할 수 있다.
- 멀티프로세싱
멀티프로세싱은 하나의 프로세스 안에서 서브 프로세스를 추가로 생성해 병렬로 작업을 처리하는 방식을 말한다.
Celery 자체적으로는 worker 하위에 멀티프로세싱을 지원하지 않는다.
하지만 특정 작업에서 멀티프로세싱이 필요하다면,
Celery worker 안에 직접 서브 프로세스를 만들어서 처리하는 방식을 사용할 수 있다.
- 코루틴
Celery worker 내에서 코루틴을 사용하여 단일 프로세스 내에서 여러 작업을 동시에 처리할 수 있다.
| Multiprocessing | Coroutine | |
| 작업 처리 방식 | 다중 프로세스, 병렬 처리 | 단일 프로세스, 비동기 동시성 처리 |
| CPU 활용 | 다중 CPU 코어 사용 가능 | 단일 CPU 코어만 사용 |
| 적합한 작업 유형 | CPU 바운드 작업 (대규모 계산 등) | I/O 바운드 작업 (네트워크, 파일 입출력) |
| 메모리 사용 | 프로세스마다 메모리 독립 | 메모리 공유, 상대적으로 적음 |
| 성능 | CPU 집약적인 작업에서 더 좋음 | 대규모 I/O 작업에서 효율적 |
| 복잡도 | 프로세스 간 통신 필요, 복잡도가 높음 | 단일 프로세스에서 작동, 상대적으로 단순 |
작업 유형에 따라 적합한 동시성 처리 방식을 사용하면 된다.
Celery는 다양한 concurrency 옵션을 제공하여 다양한 유형의 작업을 효율적으로 처리할 수 있게 한다.
- Prefork Pool (기본)
여러 개의 worker 프로세스를 미리 생성
CPU-bound 작업에 적합
ex) celery -A app worker --concurrency=4
- Eventlet
단일 프로세스 내에서 여러 작업을 동시에 처리
그린 스레드 기반의 비동기 처리
I/O bound 작업에 적합
ex) celery -A app worker --pool=eventlet --concurrency=100
- Gevent
Eventlet과 유사한 그린 스레드 기반 처리
I/O bound 작업에 적합
ex) celery -A app worker --pool=gevent --concurrency=100
- Solo Pool
단일 프로세스로 동작
디버깅이나 특정 상황에서 유용
ex) celery -A app worker --pool=solo
? 그린스레드 (Green Threads) ?
OS 스레드 (운영체제가 관리하는 실제 하드웨어 스레드)와는 다르게,
사용자 레벨에서 관리되는 경량 스레드이다.
OS가 스레드를 스케줄링하는 대신, Python 인터프리터 내에서 스레드 스케줄링이 이루어진다.
| Green Threads (Eventlet, Gevent) | Coroutine (async/await) | |
| 실행 방식 | 여러 '가상 스레드'가 단일 OS 스레드 내에서 번갈아 실행됨 | 명시적인 async/await 구문을 통해 작업을 적환 |
| 동시성 관리 주체 | 라이브러리(Eventlet, Gevent) 내부에서 자동 처리 | 사용자 코드에서 명시적으로 제어 |
| 작업 전환 | 비동기 작업이 발생하면 그린 스레드 간에 자동 전환 | await 시 다른 비동기 함수로 전환 |
| 작업 대상 | 주로 I/O 바운드 작업 | 주로 I/O 바운드 작업 |
| 성능 | 더 많은 컨텍스트 전환을 처리할 수 있으나, 코루틴보다 약간의 오버헤드가 있음 |
비교적 가볍고 더 명시적임 |
| 적용 범위 | Eventlet, Gevent가 설치된 환경에서만 동작 | 표준 Python 3.5+에서 지원 |
그린 스레드는 하나의 OS 스레드 내에서 실행된다.
즉, 실제로는 단일 OS 스레드가 작업을 수행하지만 이 안에서 그린 스레드들이 교대로 실행된다.
여러 그린 스레드가 돌아가는 것처럼 보이지만 실제로는 하나의 OS 스레드가 전환하면서 처리하고 있는 것이다.
이 전환은 비동기 작업(예: I/O 대기)시 자동으로 이루어진다.
Python 자체가 각 그린 스레드의 실행을 관리하는 것이고
각 그린 스레드가 I/O 대시 상태에 있을 때 다른 그린 스레드가 CPU를 차지하여 작업을 이어서 수행한다.
반면 코루틴은 함수 수준에서 비동기 코드를 작성한다.
여기서 '함수 수준'이라는 말은 코루틴이 특정 함수 단위로 전환될 수 있다는 것을 의미한다.
코루틴에서 async 함수는 CPU-bound 작업을 하지 않고,
특정 시점에서 명시적으로 await을 통해 다른 작업으로 전환된다.
프로그래머가 언제, 어떤 작업을 대기 상태로 만들고, 다른 작업을 재개할지 직접 제어하는 것이 코루틴의 핵심이다.
즉, 코루틴은 작업이 실행될 때 직접 전환을 요청해야 하는 반면,
그린 스레드는 OS 스레드처럼 자동으로 전환된다.
코루틴은 함수가 비동기 작업을 만났을 때만 명시적으로 다른 작업으로 넘어가고,
그린 스레드는 I/O 대기 시 자동으로 다른 작업으로 전환되는 방식이다.
# Gevent 예시
import gevent
from gevent import monkey; monkey.patch_all()
import time
def task1():
print("Task 1 start")
time.sleep(1) # Gevent가 자동으로 전환
print("Task 1 end")
def task2():
print("Task 2 start")
time.sleep(1)
print("Task 2 end")
gevent.joinall([gevent.spawn(task1), gevent.spawn(task2)])# 코루틴 예시
import asyncio
async def task1():
print("Task 1 start")
await asyncio.sleep(1) # 명시적으로 await을 통해 전환
print("Task 1 end")
async def task2():
print("Task 2 start")
await asyncio.sleep(1)
print("Task 2 end")
async def main():
await asyncio.gather(task1(), task2())
asyncio.run(main())'Python > 파이썬 고급' 카테고리의 다른 글
| [Python] lock 사용법 (0) | 2023.10.04 |
|---|
[Python] 코루틴 사용법
asyncio.run()
이 함수는 외부에서 호출되며,
코루틴을 실행하기 위한 새로운 이벤트 루프를 생성하고, 코루틴이 완료될 때까지 이벤트 루프를 실행한 후 종료
기본적으로 프로그램의 진입점에서 한 번 사용
asyncio.create_task()
이벤트 루프 내에서 비동기적으로 실행할 코루틴을 task로 스케쥴링
이렇게 생성된 task는 즉시 이벤트 루프에 의해 실행되며 task의 완료를 기다리지 않고 다음 줄의 코드가 실행됨
await
코루틴 실행을 일시 중단하고, 해당 코루틴이 완료될 때까지 현재 코루틴의 실행을 중지
완료되면, await 다음의 코드가 실행됨
비동기 작업이 완료될 때까지 기다려야 할 경우에 사용
ex) 특정 데이터를 받아와야 다음 단계의 코드를 실행할 수 있는 경우
await는 비동기 작업의 완료를 기다리지만, 전통적인 blocking 방식과는 다름
블록킹 방식에서는 작업이 완료될 때까지 프로그램의 실행히 완전히 멈춤
반면, 비동기 방식에서는 await으로 특정 작업의 완료를 기다리는 동안 이벤트 루프가 다른 비동기 작업을 수행할 수 있게 해줌
완료를 기다리지만 다른 작업을 수행할 수 있게 한다?
이해가 잘 안된다.
예시를 보자.
1. await을 만난 비동기 작업 A는 I/O 작업 등으로 인해 완료를 기다려야 한다.
2. 이벤트 루프는 작업 A가 완료될 때까지 대기하고 있을 동안, 다른 준비된 비동기 작업 B를 실행한다.
3. 작업 B도 await을 만나면, 이벤트 루프는 다시 다른 준비된 작업(ex: 작업 C)으로 전환할 수 있다.
4. 이 과정을 통해, 이벤트 루프는 실행 가능한 비동기 작업을 계속 찾아 실행하며, 각 작업의 대기 시간을 효율적으로 활용한다.
결국, await으로 인해 기다려야 하는 특정 작업이 있더라도, 프로그램 전체가 멈추는 것이 아니라,
가능한 다른 작업들을 계속해서 처리할 수 있다.
이것이 바로 비동기 프로그래밍이 제공하는 동시성의 이점이다!
import asyncio
import datetime
async def my_task(num, second):
start_time = datetime.datetime.now()
print(f"Task {num} 시작")
await asyncio.sleep(second) # second초 후에 작업이 완료됩니다.
end_time = datetime.datetime.now()
print(f"Task {num} 완료")
return end_time - start_time
async def main():
start_time = datetime.datetime.now()
# my_task를 태스크로 스케줄링합니다.
# 태스크는 즉시 이벤트 루프에 의해 실행되지만, main()의 흐름은 여기서 멈추지 않습니다.
task1 = asyncio.create_task(my_task(1, 2))
# 이 시점에서 main()의 다음 줄로 바로 넘어갑니다. 태스크의 완료를 기다리지 않습니다.
print("main()의 다음 코드 실행")
task2 = asyncio.create_task(my_task(2, 5))
# 그러나 여기서 await을 사용하여 태스크의 완료를 기다립니다.
duration1 = await task1
duration2 = await task2
end_time = datetime.datetime.now()
print(f"Task 1 소요 시간: {duration1}")
print(f"Task 2 소요 시간: {duration2}")
print(f"main 함수의 전체 실행 시간: {end_time - start_time}")
# 이벤트 루프를 시작하고 main() 코루틴을 실행합니다.
asyncio.run(main())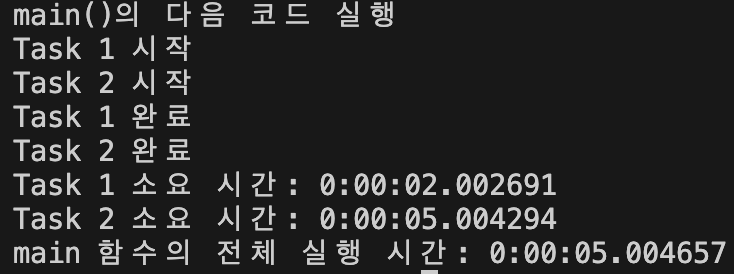
전체 실행 시간이 7초가 아닌 5초로 단축됐다.
asyncio.Future()
비동기 작업의 결과를 나타내는데 사용되는 객체
아직 완료되지 않은 작업을 추적하고, 해당 작업이 완료되면 결과를 저장, 이후 결과 조회 가능
* Future 객체의 주요 메서드 *
cancel() : Future의 작업 취소, 작업이 이미 완료되었거나 취소되었다면 효과 없음
cancelled() : Future의 작업이 취소되었는지 여부 반환
done() : Future의 작업이 완료되었는지 여부 반환
result() : Future의 결과 반환, Future가 아직 완료되지 않았다면, 호출자를 block
set_result() : Future의 결과를 설정, Future가 완료되었음을 알리며, result() 호출에 의해 반환될 값 설정
asyncio.gather()
주어진 코루틴이나 Future 객체들을 동시에 실행하고, 모든 결과를 하나의 리스트로 반환
gather로 실행 중인 코루틴이라 Future 객체들이 독립적을 실행되고,
서로의 완료를 기다리지는 않음
import asyncio
async def worker(future):
print('Worker: Starting work')
await asyncio.sleep(1)
print('Worker: Done with work')
future.set_result('Worker result')
async def boss(future):
print('Boss: Waiting for worker to finish')
result = await future
print(f'Boss: Received result: {result}')
async def main():
future = asyncio.Future()
await asyncio.gather(boss(future), worker(future))
asyncio.run(main())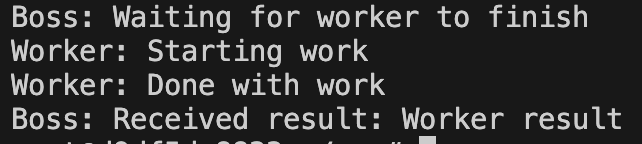
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 어노테이션(annotation), typing (0) | 2023.04.10 |
|---|---|
| [Python] 코루틴 (Coroutine) (0) | 2023.02.16 |
| [Python] 이터레이터(iterator), 제너레이터(generator) (0) | 2022.12.14 |
| [Python] setdefault 함수 (0) | 2022.12.11 |
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
[Python] lock 사용법
.lock 파일
파일 락(lock)을 관리하고 다른 프로세스 또는 스레드와의 충돌을 방지하기 위해 사용되는 파일
일반적으로 어떤 프로세스가 파일을 사용하고 있는지 나타내는 역할
파일을 쓰고 있는 동안 다른 프로세스나 스레드가 해당 파일을 동시에 수정하려고 할 때 충돌이 발생하는 것을 방지
파일 접근제어
.lock 파일이 있는 경우
이 파일을 소유한 프로세스만 해당 파일을 수정할 수 있으며,
다른 프로세스는 접근을 시도할 때 대기하거나 충볼을 방지하기 위한 작업을 수행
파일 락 해제
파일 작업이 완료되면 해당 파일의 락(lock)을 해제
이는 다른 프로세스나 스레드가 해당 파일을 수정할 수 있도록 허용하는 역할
동기화
.lock 파일은 데이터베이스 파일 또는 다른 공유 리소스에 대한 동기화에 사용될 수 있음
락 걸기 (Locking)
파일을 락으로 설정하여 다른 프로세스 또는 스레드의 접근을 제한
주로 사용되는 락 함수로는 fcntl(파일 컨트롤) 또는 flock(파일 락)과 같은 POSIX 표준 라이브러리가 있음
프로세스 간 동기화를 위해 뮤텍스(Mutex)나 세마포어(Semaphore)와 같은 동기화 기법을 사용할 수 있음
import fcntl
file = open("example.txt", "w")
# 파일 락 걸기
fcntl.flock(file.fileno(), fcntl.LOCK_EX)
# 파일을 안전하게 수정 가능
# 파일 락 해제
fcntl.flock(file.fileno(), fcntl.LOCK_UN)
file.close()락 해제 (Unlocking)
파일 락을 해제하여 다른 프로세스나 스레드의 접근을 허용
fcntl 이나 flock을 사용하여 파일 락을 걸었다면, 해당 라이브러리 함수를 호출하여 락을 해제
뮤텍스나 세마포어를 사용한 경우,
해당 뮤텍스나 세마포어의 해제 함수를 호출하여 다른 프로세스에게 리소스를 반환
import fcntl
file = open("example.txt", "w")
# 파일 락 해제
fcntl.flock(file.fileno(), fcntl.LOCK_UN)
file.close()
파일 락을 제대로 사용하지 않으면 데이터 무결성 문제가 발생할 수 있으므로 주의 필요
'Python > 파이썬 고급' 카테고리의 다른 글
| [Python] BackgroundTasks, Celery (0) | 2024.09.06 |
|---|
[Python] 파이썬 실행 과정 (Python Compile)
Python 소스 코드 compile과 Python interpreter compile를 알아보자.
목적 : 개발 서버에 파이썬으로 개발한 백엔드 코드를 배포
아래는 Dockerfile의 일부이다.
# Python 3.8 설치
RUN curl -O https://www.python.org/ftp/python/3.8.12/Python-3.8.12.tgz \
&& tar xzf Python-3.8.12.tgz \
&& cd Python-3.8.12 \
&& ./configure --enable-optimizations \
&& make altinstall
각 명령어의 의미는 다음과 같다.
- ./configure --enable-optimizations
- Python을 컴파일하기 위한 설정을 수행
- --enable-oprimizations 플래그는 Python 실행 속도를 향상시키는 최적화 옵션을 활성화
- make altinstall
- 설정된 옵션으로 Python을 컴파일하고 시스템에 설치
- 기존의 Python 인터프리터와 충돌하지 않도록 새로운 버전의 Python을 설치
파이썬 코드는 인터프리터를 통해 실행되는 인터프리터 언어이다.
하지만 앞서 "Python을 컴파일"이라는 언급이 있었다.
이에 Python을 컴파일 한다는 것에 대한 의미를 알아보고자 한다.
Python 컴파일
파이썬은 일반적으로 인터프리터 언어로 알려져 있지만,
실제로는 "컴파일과 인터프리트 과정이 결합되어 사용"된다.
파이썬 코드의 실행은 다음과 같다.
1. 파이썬 코드는 소스 코드 형태로 작성
2. 이 코드는 인터프리터에 의해 한 줄씩 읽혀지고 해석됨
위와 같은 과정을 거쳐 파이썬 코드가 실행되며, 코드의 결과를 즉시 확인할 수 있다.
이런 특성 때문에 파이썬은 동적이고 유연한 개발 환경을 제공한다.
하지만 파이썬 코드는 실행하기 전에 일부 변환 과정을 거친다.
변환 과정은 파이썬 소스 코드를 바이트 코드(Bytecode)라는 중간 형태로 컴파일 되어 저장됨을 의미한다.
여기서 바이트 코드란 파이썬 가상 머신(Interpreter)에서 실행되는 인터프리터 언어다.
파이썬 가상 머신(Interpreter)
- 바이트코드는 파이썬 인터프리터에 의해 실행되며, 해당 코드를 실행하는 인터프리터를 가상머신이라고 부름
- 파이썬 가상머신은 파이썬 인터프리터와 그 실행을 위한 런타임 환경을 의미하는 용어로 사용
따라서 파이썬 코드를 실행할 때
실제로는 컴파일 된 바이트 코드를 인터프리터가 해석하고 실행하는 것이다.
이렇게 컴파일 된 바이트 코드는 '.pyc' 또는 'pyo' 파일로 디스크에 캐싱될 수 있어
이후 실행 시간을 단축시키는 데 도움을 준다.
해당 파일은 __pycache__디렉토리에 저장된다.
이후 실행 중인 파이썬 모듈이 변경되면,
인터프리터는 해당 모듈의 소스 코드를 다시 컴파일하여 새로운 '.pyc'파일을 생성하게 되고,
이후 실행 시에 재사용되며 동일한 모듈이 다시 임포트될 때 불필요한 컴파일 과정을 거치지 않는다.
__pycache__디렉토리
파이썬 프로젝트를 관리하면서 생성된 컴파일된 바이트 코드 파일을 저장하는 임시 디렉토리
이와 반대로 컴파일 언어는 컴파일러를 통해 바로 기계어로 변환한다.
컴파일 과정에서 소스 코드의 구문을 분석하고,
컴퓨터가 이해할 수 있는 기계어로 변환하는 중간 파일 또는 실행 파일을 생성한다.
이 과정에서 바이너리 코드가 생성되며, 이는 컴퓨터가 직접 실행할 수 있는 형태의 코드이다.
이로써 파이썬 소스 코드 컴파일에 대해 알게 되었다.
하지만 Dockerfile에 작성한 명령어는 아직 파이썬 소스 코드를 생성하기 이전이다.
어떤 것을 컴파일 한다는 것일까?
사실 make altinstall 명령어의 정확한 의미는
Python 컴파일이 아닌 Python 인터프리터 컴파일이다.
Python 인터프리터 (CPython) 컴파일
파이썬의 기본 인터프리터는 CPython이다.
이는 파이썬 프로그램을 실행하는 역할을 한다.
CPython은 C언어로 작성되어 있다.
따라서 CPython 소스 코드를 컴파일하여 실행 가능한 바이너리 형태로 변환하고
이후 생성된 바이너리는 운영 체제에서 실행할 수 있는 형태로 되어 있으며,
이를 통해 파이썬 코드를 실행할 수 있게 된다.
따라서 make altinstall은 C 언어 컴파일러를 사용해 CPython 소스코드를 컴파일 하는 단계를 수행한다.
앞서 설명한 Python 코드의 컴파일은 CPython이 소스 코드를 해석하고 실행하기 위해 내부적으로 수행하는 과정이며
make altinstall과는 별개의 단계이다.
Python 소스 코드의 compile 의미와
Python interpreter compile 의미는 다르다 !
'Python > 메모' 카테고리의 다른 글
| [Python] 구현한 모듈 import하기 (0) | 2023.05.23 |
|---|---|
| [Python] vars() (0) | 2023.05.22 |
| 주피터 노트북 시작 폴더 변경하기 (0) | 2022.10.13 |
| 아나콘다 설치 및 주피터 노트북 실행 (1) | 2022.10.12 |
[Python] 구현한 모듈 import하기
아래와 같은 폴더 구조를 가정하자.
📁 source
└ 📁 vo
└ dataVO.py
└ 📁 util
└ mongoDBUtil.py
main.py
실행할 파일이 main.py라면
mongoDBUtil의 import 경로는 main.py를 기준으로 한다.
# main.py
import source.util.mongoDBUtil
mongoDBUtil.메소드명()
mongoDBUtil.py에서 dataVO.py를 imprort할 경우에도 기준은 main.py가 된다. (실행파일)
따라서 같은 source 폴더 밑에 위치하고 있더라도 main.py파일 기준으로 source를 포함한 경로를 적어줘야 한다.
# mongoDBUtil.py
import source.vo.dataVO
📁 source
└ 📁 vo
└ dataVO.py
└ 📁 util
└ mongoDBUtil.py
└ main.py
위와 같이 main.py도 source 폴더 밑에 위치하고 있다면
source.을 제외하고 import한다.
[Python] from과 import
import import 모듈명 형식으로 사용합니다. 모듈 전체를 임포트합니다. 임포트한 모듈의 이름을 사용하여 모듈 내의 함수, 변수, 클래스 등에 접근합니다. 사용 시 모듈명을 함께 사용해야 합니다.
sso-y.tistory.com
'Python > 메모' 카테고리의 다른 글
| [Python] 파이썬 실행 과정 (Python Compile) (0) | 2023.06.01 |
|---|---|
| [Python] vars() (0) | 2023.05.22 |
| 주피터 노트북 시작 폴더 변경하기 (0) | 2022.10.13 |
| 아나콘다 설치 및 주피터 노트북 실행 (1) | 2022.10.12 |
[Python] vars()
vars()
파이썬 내장 함수
객체의 속성과 값으로 이루어진 딕셔너리 반환
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
person = Person("John", 30)
print(vars(person)){'name': 'John', 'age': 30}
'Python > 메모' 카테고리의 다른 글
| [Python] 파이썬 실행 과정 (Python Compile) (0) | 2023.06.01 |
|---|---|
| [Python] 구현한 모듈 import하기 (0) | 2023.05.23 |
| 주피터 노트북 시작 폴더 변경하기 (0) | 2022.10.13 |
| 아나콘다 설치 및 주피터 노트북 실행 (1) | 2022.10.12 |
[Python] VO, DTO, DAO
아래 소개할 객체는 객체지향 프로그래밍에서 데이터를 캡슐화하여 전달하는 목적으로 사용되는 클래스다.
객체지향 프로그래밍에서 객체를 만들려면
바로 만들지 못하고 항상 클래스를 만든 후 해당 클래스를 이용해 객체를 만들어야 한다.
VO (Value-Object, 값 객체)
주로 데이터의 불변성(immutable)을 강조
데이터의 상태를 나타내기 위한 클래스
VO 클래스의 인스턴스는 한 번 생성되면 그 값을 변경할 수 없음 (읽기만 가능)
class PersonVO:
def __init__(self, name, age):
self.name = name
self.age = age
def get_name(self):
return self.name
def get_age(self):
return self.ageDTO (Data-Transfer-Object, 데이터 전송 객체)
데이터를 전송하고 전달받기 위한 목적으로 사용되는 클래스
로직을 갖고 있지 않은 순수한 데이터 객체
DTO 클래스의 인스턴스는 데이터를 변경할 수 있음 (읽기, 수정 가능)
class PersonDTO:
def __init__(self):
self.name = None
self.age = None
def get_name(self):
return self.name
def set_name(self, name):
self.name = name
def get_age(self):
return self.age
def set_age(self, age):
self.age = ageDAO (Data-Access-Object, 데이터 접근 객체)
데이터베이스, 파일 시스템 등과 같은 영구 저장소에 접근해 데이터를 조작하는 역할을 담당하는 객체
비즈니스 로직과 데이터 접근 로직을 분리하기 위해 사용
일반적으로 CRUD 작업을 수행
데이터 엑세스 로직을 캡슐화하고, 클라이언트 코드에서는 DAO메서드를 호출해 데이터 조작을 수행
import sqlite3
class StudentDAO:
def __init__(self, db_path):
self.connection = sqlite3.connect(db_path)
self.cursor = self.connection.cursor()
def create_student(self, student):
self.cursor.execute("INSERT INTO students (name, age) VALUES (?, ?)", (student.name, student.age))
self.connection.commit()
def get_student(self, student_id):
self.cursor.execute("SELECT * FROM students WHERE id=?", (student_id,))
row = self.cursor.fetchone()
if row:
student = Student(row[0], row[1], row[2])
return student
else:
return None
def update_student(self, student):
self.cursor.execute("UPDATE students SET name=?, age=? WHERE id=?", (student.name, student.age, student.id))
self.connection.commit()
def delete_student(self, student_id):
self.cursor.execute("DELETE FROM students WHERE id=?", (student_id,))
self.connection.commit()
def close(self):
self.cursor.close()
self.connection.close()[Python] strftime과 strptime
strftime (string format time)
날짜와 시간을 지정된 형식의 문자열로 변환
from datetime import datetime
# 현재 날짜와 시간 객체 생성
now = datetime.now()
# 날짜 및 시간 객체를 원하는 형식의 문자열로 변환
formatted_date = now.strftime("%Y-%m-%d")
formatted_time = now.strftime("%H:%M:%S")
formatted_datetime = now.strftime("%Y-%m-%d %H:%M:%S")
# 변환된 문자열 출력
print("Formatted Date:", formatted_date)
print("Formatted Time:", formatted_time)
print("Formatted DateTime:", formatted_datetime)Formatted Date: 2023-05-18
Formatted Time: 09:30:00
Formatted DateTime: 2023-05-18 09:30:00
strptime (string parse time)
주어진 형식의 문자열을 파싱하여 해당하는 날짜 및 시간 객체를 생성
from datetime import datetime
# 문자열을 날짜 및 시간 객체로 변환
date_string = "2023-05-18"
time_string = "09:30:00"
datetime_string = "2023-05-18 09:30:00"
date_object = datetime.strptime(date_string, "%Y-%m-%d")
time_object = datetime.strptime(time_string, "%H:%M:%S")
datetime_object = datetime.strptime(datetime_string, "%Y-%m-%d %H:%M:%S")
# 변환된 날짜 및 시간 객체 출력
print("Date Object:", date_object)
print("Time Object:", time_object)
print("DateTime Object:", datetime_object)Date Object: 2023-05-18 00:00:00
Time Object: 1900-01-01 09:30:00
DateTime Object: 2023-05-18 09:30:00
'Python > 파이썬 초급' 카테고리의 다른 글
| [Python] from과 import (0) | 2023.05.22 |
|---|---|
| [Python] 생성자 소멸자 (0) | 2022.11.20 |
| [Python] class (클래스와 인스턴스) (0) | 2022.11.19 |
| [Python] import (0) | 2022.11.19 |
| [Python] 가변인자 (0) | 2022.11.14 |