분류 전체보기
-
LiteLLM vs Pydantic AI 2025.10.17
-
AI Agent란? 2025.10.16
-
[Git] 원격 저장소 연결 2025.10.13
-
Keepalived + HA Proxy 이중화 구성 2025.06.12
-
 [Docker] commit & save 반영되지 않을 때 (volume) 2025.05.30
[Docker] commit & save 반영되지 않을 때 (volume) 2025.05.30 -

-
Docker compose extra_hosts: 컨테이너 내부 DNS 설정 2025.03.10
-
ssh 키 설정 + alias로 계정만으로 ssh 접속하기 2025.02.20
LiteLLM vs Pydantic AI
LiteLLM
LLM 모델 호출 통합 레이어(wrapper)
OpenAI 포맷 통합 SDK
모델마다 SDK가 달라도 completion(model=..., messages=...) 같은 OpenAI 형식 입/출력으로 통합 제공
하지만 모든 모델이 원래 OpenAI API를 지원하는 건 아님
ex) Gemini(Google AI Studio)
: 자체 API를 사용하지만 LiteLLM은 이를 OpenAI API와 동일한 인터페이스로 감싸서 호출 가능
일부 모델에는 추가 파라미터 제공
원래는 모델별 SDK가 제각각이라 SDK마다 호출 방식, 파라미터, 반환 구조가 달라서 번거로움
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(model="gpt-4o", messages=[...])
from anthropic import Anthropic
client = Anthropic()
response = client.messages.create(model="claude-3-opus", messages=[...])LiteLLM을 사용해 모델 호출을 통합된 포맷으로 감쌀 수 있음
from litellm import completion
# OpenAI 모델 호출
response = completion(
model="gpt-4o",
messages=[{"role": "user", "content": "hi"}]
)
# 다른 모델 호출
response = completion(model="anthropic:claude-3", messages=[...])
response = completion(model="mistral:open-mixtral", messages=[...])
- 모델마다 다른 SDK API 차이를 LiteLLM이 통일된 호출 인터페이스로 감쌈
- OpenAI, Anthropic, Mistral 등 거의 모든 주요 LLM을 동일한 방식으로 호출 가능
- "순수 모델 호출 SDK" 역할이므로 Agent, Tool 호출, Memory, MCP 등은 직접 구현해야 함
PydanticAI
LLM기반 Agent Framework
from pydantic_ai import Agent
agent = Agent(model="openai:gpt-4o-mini")
result = agent.run("Summarize this text")위 코드로 모델 호출, 응답 파싱, 타입 검증, Agent/Workflow 관리까지 자동 처리 가능
= 앱 수준에서 LLM을 쉽게 연결하고 타입 안전하게 결과를 다룰 수 있는 고수준 프레임워크
PydanticAI는 Model + Provider + profile 구조로 되어 있음
1. Model: LLM 호출 형식 정의 (OpenAIChatModel, AnthropicModel 등)
2. Provider: 실제 요청 전송 및 인증 처리 (OpenAIProvider, LiteLLMProvider 등)
3. Profile: 모델별 세부 규칙 (JSON schema 제한, temperature 기본값 등)
원래 PydanticAI는 모델 호출 시 각 모델 SDK에 맞춰서 호출해야 했음
최근 PydanticAI에서 LiteLLMProvider를 제공!
: PydanticAI에서 LiteLLM을 Provider로 연결하면 OpenAI API 포맷으로 감싸서 호출 가능
Agent/Workflow/타입 검증 등 PydanticAI 기능을은 그대로 쓰면서 실제 모델 호출은 LiteLLM이 처리 가능
지원하지 않는 모델은 자체 Provider 개발
'자연어 처리 > LLM' 카테고리의 다른 글
| AI Agent란? (0) | 2025.10.16 |
|---|
AI Agent란?
AI Agent
스스로 환경을 인식하고 목표를 달성하기 위해 행동을 선택하는 시스템
Agent를 구성하는 주요 개념들
| 구성요소 | 역할 | 대표 기술/예시 | |
| 기본 | LLM | 언어 이해, 계획, 추론 | GPT-4, Claude, Gemini, Llama |
| 실행 | Tools (Function Calls) |
외부 API, RAG, DB 질의 등 실행 | OpenAI Function Calling, LangChain Tools |
| 표준화 | MCP (Model Context Protocol) |
표준 연결 인터페이스 여러 도구나 시스템을 LLM에 연결하는 공통 규격 |
OpenAI MCP, Vercel MCP, Anthropic MCP |
| 고도화 | Memory | 장기/단기 기억, 상태 유지 | LangGraph Memory, vector store |
| 지식 | RAG (Retrival-Augmented Generation) |
검색 기반 지식보강 도구 LLM이 모르는 정보를 벡터DB 등에서 검색 |
LlamaIndex, LangChain Retrieval |
| 확장 | Multimodal | 여러 입력 모달리티(텍스트 이미지, 음성, 영상) 지원 | GPT-4o, Gemini, Claude 3.5등 |
| 고도화 | Planning / Reasoning Loop | LLM이 도구를 순서대로 사용할 계획을 세움 | ReAct, Tree-of-Thoughts, AutoGPT |
| 프레임워크 | Framework / Agent Runtime | 위 모든 걸 자동 orchestration | LangChain, OpenAI Agents, CrewAI, LlamaIndex Agents |
Agent = LLM + (필요한 부가 구성 요소 조합)
AI Agent 유형
| 유형 | 역할 / 특징 | 필요한 구성요소 예시 |
| 대화형 (Chat Agent) | 단순 Q&A, 자연어 이해/응답 | LLM |
| 검색형 (RAG Agent) | 외부 정보 검색 + 답변 생성 | LLM + RAG Tool |
| 행동형 (Action / Tool Agent) | 도구 호출, 계산, API 사용 | LLM + Function Calls / Tools |
| 멀티스텝 플래너형 (Planner Agent) | 목표 달성을 위해 여러 단계 계획 | LLM + Planning Loop + Tools + Memory |
| 멀티모달형 (MultiModal Agent) | 텍스트, 이미지, 음성, 영상 입력/출력 | LLM(Multimodal) + Tools + Interface |
| 지속/상태 기반(Stateful Agent) | 기억, 세션 유지, 이전 대화 맥락 활용 | Memory + LLM + Tools |
| 자동화/자율형 (Autonomous Agent) | 목표 기반 반복 수행, 스스로 판단 | Planner + Memory + Tools + Multi step Loop |
'자연어 처리 > LLM' 카테고리의 다른 글
| LiteLLM vs Pydantic AI (0) | 2025.10.17 |
|---|
[Git] 원격 저장소 연결
git init
로컬 폴더를 Git 저장소로 초기화하는 명령어
아직 코드, 브랜치, 원격 연결 없음
이 시점엔 완전히 빈 Git 저장소 상태
git remote add origin https://~
origin 이라는 이름으로 원격 Git 서버(GitLab, GitHub 등)랑 연결
아직 원격에서 코드는 가져오지 않음
git fetch origin
원격의 모든 브랜치 목록과 커밋 기록이 다운됨
로컬 브랜치로 전환되지 않음
ex) origin/main, origin/branch 같은 원격 브랜치가 생겼을 뿐 아직 내 로컬에는 아무 브랜치 없음
git branch -r
원격 브랜치 목록 보기
git checkout -b my_branch origin/my_branch
원격의 my_branch 브랜치를 기반으로 로컬에서도 my_branch라는 브랜치 만들기
- my_branch라는 로컬 브랜치가 새로 생김
- 그 브랜치 원격 origin/my_branch를 track하게 설정됨
- 동시에 그 브랜치로 전환(checkout) 됨
git branch
현재 로컬 브랜치 목록 보기
* 가 붙은게 현재 내가 작업 중인 브랜치
ex) my_branch만 가져온경우 로컬에 my_branch만 존재하고 main은 아직 원격에만 있음
main브랜치도 보고싶은 경우 git checkout -b main origin/main 실행
git push origin main 또는 git push origin my_branch
현재 로컬 main, my_branch 브랜치를 원격의 main, my_branch로 올리기
'Git' 카테고리의 다른 글
| [Git] Git과 GitHub의 차이 (0) | 2023.01.24 |
|---|
Keepalived + HA Proxy 이중화 구성
서비스 중단 없이 요청을 분산하고, 서비스 장애 시 자동으로 다른 서버로 전환되게 하려 한다.
Keepalived + HAProxy (또는 LVS) 조합을 통해 failover + load balancing을 구현하는 방법을 정리한다.
| Failover | 서버 하나가 죽었을 때, 다른 서버가 자동으로 역할을 대신하는 것 (고가용성 보장) |
| Load Balancing | 여러 서버에 요청을 분산시켜서 부하를 나눠주는 것 (성능 및 부하 분산) |
| Keepalived | 원래는 LVS 설정 자동화를 위해 만들어진 도구이지만, 현재는 VRRP를 이용한 VIP Failover 기능이 주 용도 |
| LVS (Linux Virtual Server) | 리눅스 커널 레벨에서 제공하는 고성능 로드밸런싱 기능 (TCP 연결만 분산) |
| HAProxy | 유저 공간에서 동작하는 소프트웨어 기반 로드밸서 (TCP/HTTP 레벨) |
| VIP (Virtual IP) | 실제 물리 IP가 아닌, 여러 서버가 공유할 수 있는 가상 IP 주소. 하나만 "활성" 상태이고 Failover 시 다른 서버로 넘어감 |
Keepalived란?
Keepalived는 서버 간의 **가상 IP(VIP)**를 공유하고, 장애가 발생했을 때 자동으로 다른 서버로 IP를 넘겨주는 기능을 함
즉, 서버 1대가 죽어도, 클라이언트 입장에선 IP가 그대로이기 때문에 중단 없이 서비스를 받을 수 있음
웹 서버 이중화 / 로드밸런서 이중화 / 데이터베이스 이중화 / Kubernetes HA 구성 등에 쓰인다.
기본 구성 요소
1. VRRP (Virtual Router Redundancy Protocol)
- Keepalived의 핵심 기능
- 여러 대의 서버 중 하나를 MASTER, 나머지를 BACKUP으로 설정
- MASTER가 죽으면 BACKUP이 VIP를 가져가서 대신 서비스를 함
2. Health Check
- 서버나 서비스가 살아있는지 주기적으로 확인
- 죽었으면 VIP를 넘기거나 알림을 줄 수 있음
3. LVS 구성 지원 (로드밸런싱)
- Keepalived는 원래 LVS의 설정을 자동화하기 위해 만들어졌음
- 현재는 VRRP 기능이 더 널리 쓰임
예시 시나리오
서버1 (192.168.0.101) / 서버2 (192.168.0.102) / VIP (192.168.0.100)
1. 서버1이 MASTER 역할을 맡고 VIP를 가짐
2. 클라이언트는 항상 VIP를 통해 접근함
3. 서버1이 죽으면, 서버2가 VIP를 받아서 자동으로 서비스 제공 시작
4. 클라이언트는 아무것도 모른 채 계속 서비스 이용 가능
# MASTER 설정 예시
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.0.100
}
}
# BACKUP은 state BACKUP, priority만 낮추면 됨
여기까지는 VIP 장애조치만 가능하고 로드밸런싱은 불가하다.
| Keepalived만 사용 | VIP 장애조치만 가능, 로드밸런싱은 불가 |
| Keepalived + HAProxy | FastAPI, 웹 서비스 등 HTTP 기반에 적합 |
| Keepalived + LVS | TCP 기반 단순 서비스에 고성능 분산 필요할 때 사용 |
| HAProxy 단독 사용 | 로드밸런싱 가능하지만, 장애조치 기능 없음 (VIP 필요시 Keepalived 필요) |
| 항목 | HAProxy | LVS (IPVS) |
| 계층 | L4 + L7 | L4만 (TCP/UDP) |
| 기능 | HTTP 헤더 분석, 쿠키 기반 분산 가능 | 단순 연결 분산 |
| 성능 | 좋음 | 매우 뛰어남 (커널 수준) |
| 설정 난이도 | 쉽고 직관적 | 다소 복잡, 커널 모듈 필요 |
HAProxy란?
소프트웨어 기반 로드밸런서
TCP, HTTP/HTTPS 레벨의 요청 분산 가능
라운드로빈, 가중치, 최소연결 등 다양한 방식 지원
설정은 단일 텍스트 파일 /etc/haproxy/haproxy.cfg
만약 HAProxy서버가 죽는다면?
- Keepalived로 VIP를 다른 HAProxy 서버로 넘김
- 서버 2대 (서버1, 서버2), 각 서버에 FastAPI 실행
- VIP로 이중화 및 로드밸런싱 (Keepalived로 VIP 장애 조치, HAProxy로 요청 분산)
# 정상 상태
[Client 요청]
|
v
[VIP: 192.168.0.100] ← Keepalived가 서버1에 VIP 유지 중
|
v
┌────────────────────────────────────────────┐
│ 서버1 (HAProxy1 + Keepalived Master) │
│ → 자신(127.0.0.1:8000) = FastAPI │
│ → 서버2(192.168.0.102:8000) = FastAPI │
│ → 라운드로빈 방식으로 둘에 요청 분산 │
└────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────┐
│ 서버2 (HAProxy2 + Keepalived Backup) │
│ → 대기 중, VIP 없음 │
│ → FastAPI 실행 중이며, 서버1의 HAProxy가 전달하는 요청을 처리함 │
│ → 하지만 VIP가 없어 클라이언트 요청을 직접 받진 않음 │
└────────────────────────────────────────────────────────┘# 장애 발생 시
# 서버1 DOWN → VIP가 서버2로 이동됨
[Client 요청]
|
v
[VIP: 192.168.0.100] ← 이제 서버2에 있음
|
v
┌─────────────────────────────────────────────┐
│ 서버2 (HAProxy2 + Keepalived → Master 승격) │
│ → 자신(127.0.0.1:8000) = FastAPI │
│ → 서버1(192.168.0.101:8000) = 연결 실패 (DOWN)│
│ → 헬스체크로 서버1 비활성화됨 │
│ → 자신에게만 요청 전달 │
└─────────────────────────────────────────────┘
┌────────────────────────────────────────────┐
│ 서버1 (죽음) │
│ → VIP 회수됨 │
│ → 모든 서비스 응답 불가 │
└────────────────────────────────────────────┘
서버1이 다시 살아나면 Keepalived는 우선순위에 따라 VIP를 다시 서버1로 넘기거나 서버2에 유지할 수 있음
# HAProxy 설정 예시 (haproxy.cfg)
# 서버1 기준
frontend http_front
bind *:80
default_backend fastapi_backend
backend fastapi_backend
balance roundrobin
option httpchk GET /
server server1 127.0.0.1:8000 check
server server2 192.168.0.102:8000 check
# 서버2
# server server1 192.168.0.101:8000 check
# server server2 127.0.0.1:8000 check
서버1은 살아있지만 서버1의 FastAPI가 죽었을 때?
- Keepalived는 서버1 네트워크 상태가 살아있으니 VIP 이동 안함
- HAProxy가 서버1 FastAPI가 죽었다 판단 → 서버1 FastAPI를 로드밸런싱 대상에서 제외
- 요청은 서버2 FastAPI로만 전달됨
- 따라서 서비스 중단 없이 자동으로 장애 서버를 피해 요청 분산 가능
[ 헬스 체크 역할 구분 ]
* Keepalived 헬스 체크
- 주로 네트워크 레벨 (ping, 특정 포트 열림 여부 등)으로 VIP 소유 서버가 살아있는지 판단
- Keepalived에서 장애 판단 시 VIP를 다른 서버로 이동
- 보통 서버 자체가 다운됐거나 네트워크 단절 시 작동
* HAProxy 헬스 체크
- 실제 서비스 레벨(HTTP 응답 상태, 특정 엔드포인트 정상 동작 여부 등) 확인
- 특정 서버(FastAPI 인스턴스 등)가 죽었을 때 그 서버를 로드밸런싱 대상에서 제외
- VIP 이동과는 별개, VIP를 가진 서버 내에서의 로드밸런싱 대상 관리
'네트워크' 카테고리의 다른 글
| Docker compose extra_hosts: 컨테이너 내부 DNS 설정 (0) | 2025.03.10 |
|---|---|
| [네트워크] CDN이란? (0) | 2023.01.20 |
| [네트워크] REST API란 (0) | 2023.01.20 |
[Docker] commit & save 반영되지 않을 때 (volume)
개발 환경에서 호스트 경로에 소스 코드를 두고 컨테이너 볼륨으로 지정했다.
컨테이너를 올린 후 코드 수정을 해서
commit하고 save하고 load했더니 수정된 코드가 반영이 안됐다.
= 볼륨 데이터는 commit에 포함되지 않음!
Docker 컨테이너의 파일 시스템 구조

▶︎ 이미지 레이어
여러 개의 읽기 전용 레이어들이 쌓여 있는 구조
각각의 레이어는 Dockerfile의 명령어 (FROM, RUN, COPY 등)를 실행하면서 만들어짐
컨테이너를 만들면 이 이미지 위에 쓰기 가능한 컨테이너 레이어가 하나 얹혀짐
▶︎ 컨테이너 레이어
컨테이너 실행 중에 생기는 수정, 생성, 삭제된 모든 파일/디렉터리가 저장됨
단, 마운트된 경로는 제외!
> 해당 경로는 애초에 호스트 외부를 바라보도록 리디렉션되어 있음
그래서 볼륨 데이터는 이미지에도 컨테이너 레이어에도 없음
docker commit
docker commit은 컨테이너 레이어(=컨테이너 자체의 파일 시스템)만 저장
따라서 마운트된 경로는 커밋 대상이 아님
마운트된 데이터도 포함시키려면?
docker commit으로는 불가능
1. 마운트 경로 → 임시 경로 → commit → 복원
[전제 조건]
# 호스트 경로: /myproject
# 마운트: /myproject ↔ 컨테이너 내 /app/core
docker run -v /myproject:/app/core -it ubuntu bash
[1] 최초 컨테이너 /app/core → (호스트에 마운트됨)
/app/temp → (비어 있음, commit 반영을 위해 임시 폴더 만들기)
[2] 파일 수정
/app/core/main.py ← 수정됨 (호스트에 반영됨)
[3] /app/temp에 복사
/app/temp/main.py ← 복사됨 (컨테이너 내부에 존재)
[4] docker commit → temp만 이미지에 포함됨
[5] 새 컨테이너 실행 후 복원 cp /app/temp/* /app/core/
2. Dockerfile에서 COPY를 통한 이미지 재생성
FROM ubuntu
COPY ./core /app/core
'Docker & Kubernetes > [Docker]' 카테고리의 다른 글
| [Docker] 서버에 Dockerfile 생성 후 배포 (0) | 2023.06.01 |
|---|
[OpenSearch] 이중화, multi server multi node (docker-compose)
↓ OpenSearch 주요 네트워크 설정
opensearch 주요 네트워크 설정 설명
| 설정 키 | 역할 | 예시 | 설명 |
| network.host | 서버가 바인딩할 IP | 127.0.0.1 1.1.1.1 (내 IP) 0.0.0.0 |
OpenSearch가 어떤 IP에 바인딩될지 지정. 0.0.0.0은 모든 인터페이스(모든 IP 주소)를 의미 |
| network.publish_host | 다른 노드가 이 노드를 어떻게 볼지 지정하는 IP |
1.1.1.1 | 클러스터 내 다른 노드들이 이 노드와 통신할 때 사용하는 IP 일반적으로 외부에서 접근 가능한 IP로 설정 |
| transport.tcp.port | 노드 간 통신용 기본 포트 (바인드용) |
9300 | 클러스터 내부의 노드들끼리 통신하는 데 사용하는 포트 대부분 9300 |
| transport.publish_port | 노드 간 통신용 외부에 노출할 포트 |
10093 | 다른 노드가 이 노드에 접근할 때 사용할 포트 번호 보통 transport.tcp.port와 같지만, 필요 시 다르게 지정 |
| http.port | REST API 요청을 받는 포트 (바인드용) |
9200 | 사용자가 OpenSearch에 API 요청을 보내는 포트 웹 브라우저나 curl로 접속할 때 사용 |
| http.publish_port | REST API 요청을 받을 외부 노출 포트 |
10092 | 외부 클라이언트가 이 노드에 접근할 때 사용할 포트 보통 http.port와 같지만, 포트 충돌 피하려고 다르게 지정 |
바인딩 (binding)
이 IP와 PORT로 들어오는 요청을 듣겠다는 선언
(접속을 열어둔다, 포트 리슨한다 개념과 비슷)
| 설정 값 | 의미 | 외부에서 접속 가능 여부 |
| 127.0.0.1 | 로컬 전용 | ❌ (로컬에서만 접속 가능) |
| 1.1.1.1 | 이 서버의 실제 IP | ✅ (해당 IP로 들어오는 외부 요청도 응답) |
| 0.0.0.0 | 모든 IP에 바인딩 | ✅ (해당 서버가 가진 모든 IP로 요청 수신함) |
2개 server, 각 1 node
서버A (1.1.1.1) - node1 (master)
서버B (2.2.2.2) - node2 (master)
# 서버 A
version: '3'
services:
sso-os-node1:
image: opensearchproject/opensearch:2.18.0
container_name: sso-os-node1
environment:
- cluster.name=sso-cluster # OpenSearch 클러스터의 이름
- node.name=sso-os-node1 # 이 노드의 이름 (클러스터 내 고유)
- discovery.seed_hosts=1.1.1.1:10093,2.2.2.2:10093 # 클러스터 내 노드들을 찾기 위한 시드 호스트들 (IP:transport 포트)
- cluster.initial_master_nodes=sso-os-node1,sso-os-node2 # 클러스터 초기 마스터 노드 후보들 (첫 클러스터 부트스트랩 시 필요)
- network.host=0.0.0.0 # 모든 네트워크 인터페이스에서 바인딩 허용
- network.publish_host=1.1.1.1 # 다른 노드와 통신 시 공개할 IP 주소
- transport.publish_port=10093 # 노드 간 클러스터 통신에 사용되는 transport 포트 (기본은 9300)
- http.publish_port=10092 # 외부에 노출할 HTTP 포트 (REST API용, 기본은 9200)
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true" # 데모 보안 설정 설치 비활성화
- "DISABLE_SECURITY_PLUGIN=true" # 보안 플러그인 (OpenSearch Security Plugin) 비활성화
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch-data1:/usr/share/opensearch/data
ports:
- 10092:9200
- 10096:9600
- 10093:9300
networks:
- sso-opensearch-net
volumes:
opensearch-data1:
networks:
sso-opensearch-net:# 서버B
version: '3'
services:
sso-os-node2:
image: opensearchproject/opensearch:2.18.0
container_name: sso-os-node2
environment:
- cluster.name=sso-cluster
- node.name=sso-os-node2
- discovery.seed_hosts=1.1.1.1:10093,2.2.2.2:10093
- cluster.initial_master_nodes=sso-os-node1,sso-os-node2
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=0.0.0.0
- network.publish_host=2.2.2.2
- transport.publish_port=10093
- http.publish_port=10092
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- opensearch-data2:/usr/share/opensearch/data
ports:
- 10092:9200
- 10096:9600
- 10093:9300
networks:
- sso-opensearch-net
volumes:
opensearch-data2:
networks:
sso-opensearch-net:
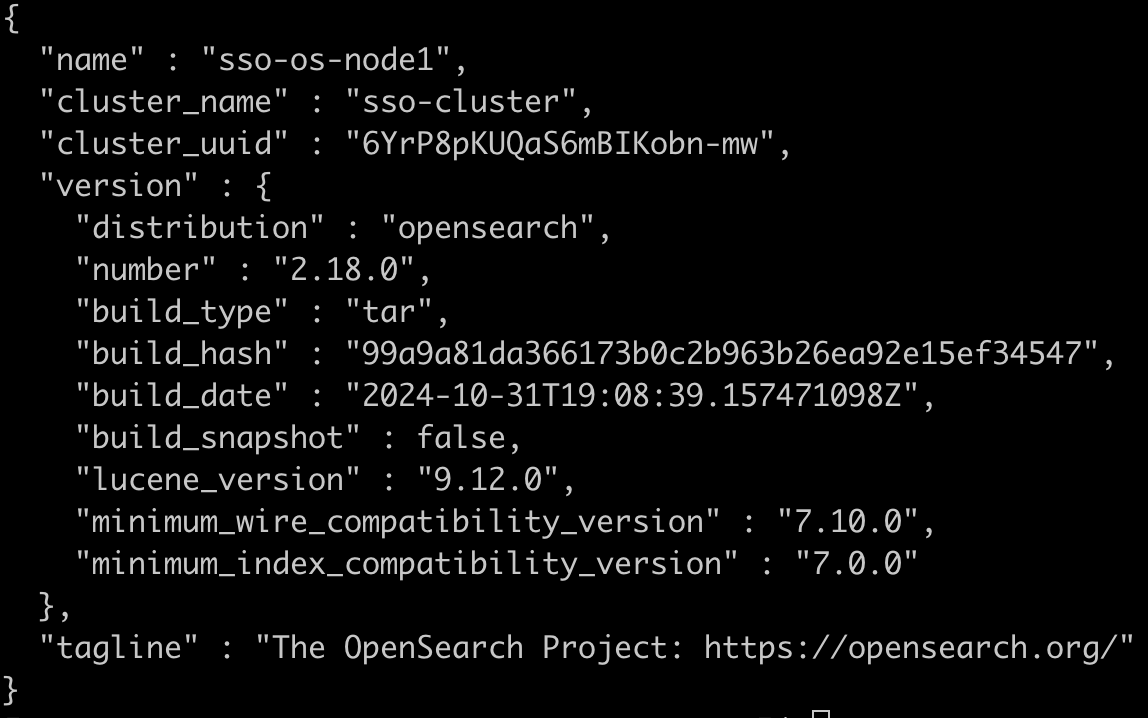

2개 server, 각 3 node
서버A (1.1.1.1) - node1 (master), node2, node3
서버B (2.2.2.2) - node4 (master), node5, node6
# 서버 A
version: '3'
services:
250512-cluster-node1:
image: opensearchproject/opensearch:2.18.0
container_name: 250512-cluster-node1
environment:
- cluster.name=250512-cluster
- node.name=250512-cluster-node1
- discovery.seed_hosts=1.1.1.1:10092,1.1.1.1:10095,1.1.1.1:10098,2.2.2.2:10092,2.2.2.2:10095,2.2.2.2:10098
- cluster.initial_master_nodes=250512-cluster-node1,250512-cluster-node4
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=0.0.0.0
- network.publish_host=1.1.1.1
- transport.publish_port=10092
- http.publish_port=10091
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- 3node-opensearch-data1:/usr/share/opensearch/data
ports:
- 10091:9200
- 10093:9600
- 10092:9300
networks:
- 250512-opensearch-net
250512-cluster-node2:
image: opensearchproject/opensearch:2.18.0
container_name: 250512-cluster-node2
environment:
- cluster.name=250512-cluster
- node.name=250512-cluster-node2
- discovery.seed_hosts=1.1.1.1:10092,1.1.1.1:10095,1.1.1.1:10098,2.2.2.2:10092,2.2.2.2:10095,2.2.2.2:10098
- cluster.initial_master_nodes=250512-cluster-node1,250512-cluster-node4
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=0.0.0.0
- network.publish_host=1.1.1.1
- transport.publish_port=10095
- http.publish_port=10094
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- 3node-opensearch-data2:/usr/share/opensearch/data
ports:
- 10094:9200
- 10096:9600
- 10095:9300
networks:
- 250512-opensearch-net
250512-cluster-node3:
image: opensearchproject/opensearch:2.18.0
container_name: 250512-cluster-node3
environment:
- cluster.name=250512-cluster
- node.name=250512-cluster-node3
- discovery.seed_hosts=1.1.1.1:10092,1.1.1.1:10095,1.1.1.1:10098,2.2.2.2:10092,2.2.2.2:10095,2.2.2.2:10098
- cluster.initial_master_nodes=250512-cluster-node1,250512-cluster-node4
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=0.0.0.0
- network.publish_host=1.1.1.1
- transport.publish_port=10098
- http.publish_port=10097
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- 3node-opensearch-data3:/usr/share/opensearch/data
ports:
- 10097:9200
- 10099:9600
- 10098:9300
networks:
- 250512-opensearch-net
volumes:
3node-opensearch-data1:
3node-opensearch-data2:
3node-opensearch-data3:
networks:
250512-opensearch-net:# 서버 B
version: '3'
services:
250512-cluster-node4:
image: opensearchproject/opensearch:2.18.0
container_name: 250512-cluster-node4
environment:
- cluster.name=250512-cluster
- node.name=250512-cluster-node4
- discovery.seed_hosts=1.1.1.1:10092,1.1.1.1:10095,1.1.1.1:10098,2.2.2.2:10092,2.2.2.2:10095,2.2.2.2:10098
- cluster.initial_master_nodes=250512-cluster-node1,250512-cluster-node4
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=0.0.0.0
- network.publish_host=2.2.2.2
- transport.publish_port=10092
- http.publish_port=10091
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- 3node-opensearch-data4:/usr/share/opensearch/data
ports:
- 10091:9200
- 10093:9600
- 10092:9300
networks:
- 250512-opensearch-net
250512-cluster-node5:
image: opensearchproject/opensearch:2.18.0
container_name: 250512-cluster-node5
environment:
- cluster.name=250512-cluster
- node.name=250512-cluster-node5
- discovery.seed_hosts=1.1.1.1:10092,1.1.1.1:10095,1.1.1.1:10098,2.2.2.2:10092,2.2.2.2:10095,2.2.2.2:10098
- cluster.initial_master_nodes=250512-cluster-node1,250512-cluster-node4
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=0.0.0.0
- network.publish_host=2.2.2.2
- transport.publish_port=10095
- http.publish_port=10094
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- 3node-opensearch-data5:/usr/share/opensearch/data
ports:
- 10094:9200
- 10096:9600
- 10095:9300
networks:
- 250512-opensearch-net
250512-cluster-node6:
image: opensearchproject/opensearch:2.18.0
container_name: 250512-cluster-node6
environment:
- cluster.name=250512-cluster
- node.name=250512-cluster-node6
- discovery.seed_hosts=1.1.1.1:10092,1.1.1.1:10095,1.1.1.1:10098,2.2.2.2:10092,2.2.2.2:10095,2.2.2.2:10098
- cluster.initial_master_nodes=250512-cluster-node1,250512-cluster-node4
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=0.0.0.0
- network.publish_host=2.2.2.2
- transport.publish_port=10098
- http.publish_port=10097
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- 3node-opensearch-data6:/usr/share/opensearch/data
ports:
- 10097:9200
- 10099:9600
- 10098:9300
networks:
- 250512-opensearch-net
volumes:
3node-opensearch-data4:
3node-opensearch-data5:
3node-opensearch-data6:
networks:
250512-opensearch-net:
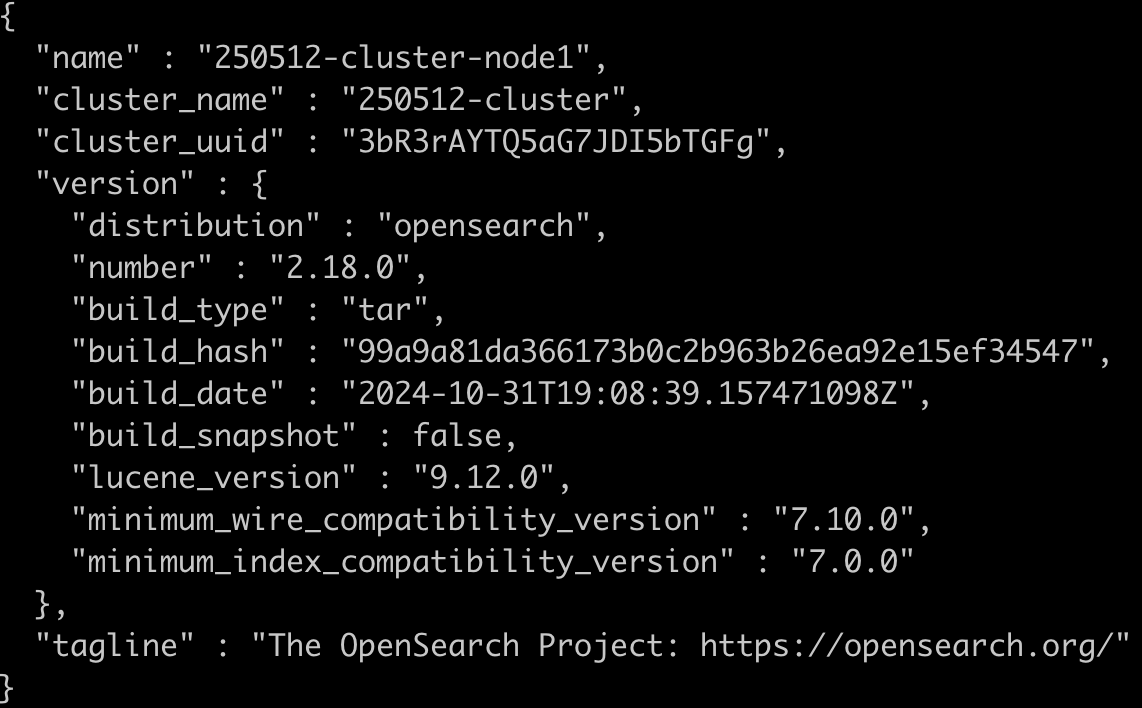

기록..
노드 1개씩 먼저 테스트 후 노드 3개로 늘려서 테스트 했었는데
discovery(각 노드들이 서로 발견)는 했지만 election(마스터 노드 선출)을 하지 못해서 클러스터 구성이 완료되지 않았었다.
docker logs를 통해 node1의 로그를 확인해보니
[WARN ][ClusterFormationFailureHelper] cluster-manager not discovered or elected yet,
an election requires a node with id [N3k2No9ATkSEu8mUQ8Uk3A],
have discovered:
{node1}, {node2}, {node3}, {node4}, {node5}, {node6}
→ 즉, node1~6까지는 살아 있음
하지만 id N3k2... 은 없음 → 그래서 마스터를 못 뽑음
→ discovery will continue... (계속 찾고는 있음)
이전 클러스터 상태에 꼭 있어야할 노드 ID가 (N3k2...)가 기록되어 있었고
예전 상태가 남아 있어 해당 노드가 없기 때문에 마스터를 못 뽑고 있던 상황이었다.
원인은
노드1개, 3개를 올렸던 docker-compose에서 볼륨을 opensearch-data1로 같이 쓰고 있었고
docker-compose down으로 볼륨까지 삭제됐다고 생각했지만 컨테이너와 네트워크를 삭제시켜주고 볼륨은 삭제되지 않았다.
따라서 opensearch-node1의 /user/share/opensearch/data 볼륨은 그대로 남아있었고
그래서 클러스터 stat 파일(nodes/, cluster-state*)도 그대로 남아있었다.
docker-compose down -v로 볼륨까지 삭제했어야했다.
---
여기까지 한 서버가 죽어도 다른 서버의 OpenSearch 노드는 계속 동작하므로 이중화가 되었다.
이중화의 핵심은 OpenSearch 자체가 클러스터링 기능을 제공하기 때문에 가능하다.
(예를 들어, FastAPI 같은 일반 앱은 이중화를 직접 구성해야 하며
로드 밸런서, DB 연결, 세션 공유 등을 별도로 설계해야하니까!)
이중화 외 자동 복구 기능을 제공하지 않는다.
따라서 컨테이너 자체가 죽거나 서버가 죽으면 수동으로 재시작이 필요하다.
-> 서비스 이중화는 되지만, 인프라 자동 복구는 없음
자동 복구 설정 (Docker Compose 기준)
컨테이너 단위 자동 복구를 위해 restart:always를 추가하면 된다.
단, 서버 자체가 죽는 경우까지 자동 복구하려면 systemd 등록 등 별도 작업이 필요하다.
services:
sso-os-node1:
...
restart: always # 컨테이너 자동 복구 설정
services:
sso-os-node2:
...
restart: always # 컨테이너 자동 복구 설정
restart까지 추가하면 OpenSearch의 클러스터링 기능 기반 이중화 + Docker Compose 수준의 자동 복구까지 포함한 구조가 된다.
지금까지는 Docker의 기본 네트워크 모드인 bridge 모드를 사용했다.
ports 매핑 없이 더 간편하게 docker-copmose를 구성하고자 한다면 host 모드를 사용할 수 있다.
| bridge | host | |
| IP/포트 | 컨테이너 고유 IP 사용 ports:로 호스트와 매핑 |
호스트 IP/포트를 그대로 공유 매핑 불필요 |
| 외부 접근 | ports: "9200:9200" 필요 | 컨테이너 내 localhost:9200 → 곧바로 호스트 9200 |
| 격리성 | 컨테이너끼리 격리 가능 | 격리 없음 (보안 약함) |
| 포트 충돌 | 없음 (외부 포트 다르게 매핑 가능) | 호스트 포트 직접 사용 → 충돌 위험 |
| 성능 | NAT 있음 (약간 느림) | NAT 없음 (조금 더 빠름) |
| 사용 예 | 운영환경, 포트 분리 필요 시 | 개발환경, 간편 테스트 시 |
아래는 host를 사용한 docker-compose 다.
2개 server, 각 2 node
서버A (1.1.1.1) - node1 (master), node2
서버B (2.2.2.2) - node3 (master), node4
# 서버 A
version: '3'
services:
host-os-node1:
image: opensearchproject/opensearch:2.18.0
network_mode: host # host 네트워크 사용 → 컨테이너가 호스트의 IP와 포트를 그대로 사용 (포트 포워딩 불필요)
container_name: host-os-node1
environment:
- cluster.name=host-cluster
- node.name=host-os-node1
- discovery.seed_hosts=1.1.1.1:9300,2.2.2.2:9300,1.1.1.1:9301,2.2.2.2:9301 # 클러스터를 구성할 때 초기 노드 목록 (서로 연결될 수 있게 IP:PORT 지정)
- cluster.initial_master_nodes=host-os-node1,host-os-node3 # 최초 마스터 후보 노드들 (클러스터 최초 부트스트랩 시 한 번만 사용됨)
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=1.1.1.1 # 이 노드가 어떤 IP에서 요청을 수신할지 지정 (호스트 IP로 설정해야 외부 통신 가능)
- transport.publish_port=9300 # 이 노드가 다른 노드들에게 자신을 알릴 때 사용할 포트
- http.publish_port=10191 # 클라이언트(사용자)가 이 노드에 REST API로 접속할 때 사용할 포트
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- host-opensearch-data1:/usr/share/opensearch/data
host-os-node2:
image: opensearchproject/opensearch:2.18.0
network_mode: host
container_name: host-os-node2
environment:
- cluster.name=host-cluster
- node.name=host-os-node2
- discovery.seed_hosts=1.1.1.1:9300,2.2.2.2:9300,1.1.1.1:9301,2.2.2.2:9301
- cluster.initial_master_nodes=host-os-node1,host-os-node3
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=1.1.1.1
- transport.publish_port=9301 # 같은 서버의 두 번째 노드이므로 포트를 다르게 지정
- http.publish_port=10192 # 이 노드의 REST API 포트
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- host-opensearch-data2:/usr/share/opensearch/data
volumes:
host-opensearch-data1:
host-opensearch-data2:
transport.publish_port=9300
이 노드가 다른 노드들에게 자신을 알릴 때 사용할 포트
→ OpenSearch는 기본적으로 첫 번째 노드는 9300 포트를 사용하고,
같은 서버에 두 번째 노드를 띄우면 9301, 그 다음은 9302... 이렇게 자동 증가함.
명확히 통신 포트를 지정해주기 위해 수동으로 지정함.
http.publish_port=10191
클라이언트(사용자)가 이 노드에 REST API로 접속할 때 사용할 포트
→ 같은 서버에 여러 노드가 있으므로 포트 충돌 방지 및 명확한 구분을 위해 지정
`network_mode: host`로 인해 이 포트가 곧바로 외부에 노출됨
`network.publish_host` 또는 `transport.publish_port`를 따로 지정하지 않은 이유:
기본적으로 `network.host`, `transport.tcp.port`값을 따라가므로 따로 지정하지 않아도 됨.
# 서버 B
version: '3'
services:
host-os-node3:
image: opensearchproject/opensearch:2.18.0
network_mode: host
container_name: host-os-node3
environment:
- cluster.name=host-cluster
- node.name=host-os-node3
- discovery.seed_hosts=1.1.1.1:9300,2.2.2.2:9300,1.1.1.1:9301,2.2.2.2:9301
- cluster.initial_master_nodes=host-os-node1,host-os-node3
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=2.2.2.2
- transport.publish_port=9300
- http.publish_port=10191
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- host-opensearch-data3:/usr/share/opensearch/data
host-os-node4:
image: opensearchproject/opensearch:2.18.0
network_mode: host
container_name: host-os-node4
environment:
- cluster.name=host-cluster
- node.name=host-os-node4
- discovery.seed_hosts=1.1.1.1:9300,2.2.2.2:9300,1.1.1.1:9301,2.2.2.2:9301
- cluster.initial_master_nodes=host-os-node1,host-os-node3
- bootstrap.memory_lock=true
- "OPENSEARCH_JAVA_OPTS=-Xms512m -Xmx512m"
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
- network.host=2.2.2.2
- transport.publish_port=9301
- http.publish_port=10192
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
volumes:
- host-opensearch-data4:/usr/share/opensearch/data
volumes:
host-opensearch-data3:
host-opensearch-data4:
Docker compose extra_hosts: 컨테이너 내부 DNS 설정
DNS (Domain Name System)
인터넷에서 도메인 이름(예: example.com)을 IP 주소(예: 1.2.3.4)로 변환하는 시스템
웹 브라우저나 애플리케이션이 도메인 이름으로 서버에 접속할 때,
DNS 서버에 요청하여 해당 도메인의 IP 주소를 알아냄
/etc/hosts 파일
컴퓨터 내부에서 DNS 조회 없이 도메인 이름과 IP 주소를 직접 매핑하는 파일
이 파일에 특정 도메인 이름과 IP 주소를 등록하면, 해당 컴퓨터에서는 DNS 서버에 문의하지 않고
/etc/hosts 파일의 정보를 사용하여 접속함
import aiohttp
import asyncio
async with aiohttp.ClientSession() as session:
async with session.get('http://example.com') as response:
print("응답 상태 코드:", response.status)
print("응답 내용:", await response.text())위 코드는 url에 지정된 주소로 HTTP POST 요청을 보냄
url에 도메인 이름(예: example.com)이 사용되었다면,
애플리케이션은 해당 도메인의 IP 주소를 알아내야 함
DNS 설정이 제대로 되어 있지 않으면 Name or Service not known 오류가 발생할 수 있음
url에 IP 주소(예: 1.2.3.4)가 직접 사용되었다면,
도메인 이름을 IP 주소로 변환하는 과정이 필요하지 않음
Docker Compose에서 extra_hosts 설정은
컨테이너 내부의 /etc/hosts 파일에 특정 호스트 이름과 IP 주소의 매핑을 추가할 수 있음
version: "3"
services:
web:
image: nginx:latest
extra_hosts:
- "example.com:1.2.3.4"
'네트워크' 카테고리의 다른 글
| Keepalived + HA Proxy 이중화 구성 (0) | 2025.06.12 |
|---|---|
| [네트워크] CDN이란? (0) | 2023.01.20 |
| [네트워크] REST API란 (0) | 2023.01.20 |
ssh 키 설정 + alias로 계정만으로 ssh 접속하기
1. SSH 키 생성 (ssh-keygen)
먼저 로컬 머신에서 SSH 키를 생성해야 한다.
* 키가 이미 존재하는지 확인
ls -l ~/.ssh/id_rsa, id_ecdsa, id_ed25519 등 여러 키가 있을 수도 있음
보통 id_rsa 또는 id_ed25519가 가장 많이 사용됨
파일이 존재하면 건너뛰고, 없으면 새로 생성
* SSH 키 생성
ssh-keygen -t rsa -b 4096 -C "your_email@example.com"옵션
-t rsa : RSA 방식의 키 생성
-b 4096 : 4069비트 길이 (더 강력한 보안)
-C "email@example.com" : 키에 주석 추가 (선택 사항)
키 생성 후 ~/.ssh 디렉토리에 id_rsa(개인키)와 id_rsa.pub(공개키)가 생성됨
2. SSH 에이전트에 키 추가 (ssh-add)
SSH 키를 사용하려면 SSH 에이전트에 추가해야 한다.
(이미 추가된 경우 생략 가능!)
* 키 추가하기
ssh-add ~/.ssh/id_rsa* 추가된 키 확인
ssh-add -l* 출력 예시
4096 SHA256:xxxxx... user@hostname (RSA)
3. 서버에 공개키 복사 (ssh-copy-id)
생성한 SSH 키를 서버로 전송하여 비밀번호 없이 접속할 수 있도록 설정
ssh-copy-id 계정@host비밀번호를 한 번 입력하면 자동으로 ~/.ssh/authorized_keys 파일에 공개키가 추가된다.
* 정상적으로 추가되었는지 확인
ssh 계정@host "cat ~/.ssh/authorized_keys"4. SSH 자동 로그인 테스트
이제 SSH 접속 시 비밀번호 없이 자동 로그인이 되어야 한다.
ssh user@192.168.1.100만약 계속 비밀번호를 묻는다면, 다음 사항을 확인해야 한다.
- 서버의 ~/.ssh/authorized_keys에 공개 키가 제대로 추가되었는지
- ~/.ssh 디렉터리와 authorized_keys 파일의 권한이 올바른지
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys5. Alias 설정
매번 ssh user@1.2.3.4를 입력하는 대신, A 한 글자로 빠르게 접속할 수 있도록 alias를 설정할 수 있다.
echo "alias A='ssh A@1.2.3.4'" >> ~/.bashrc
source ~/.bashrc이후 터미널에 A만 입력하여 바로 접속 가능하다.
'업무 > 메모' 카테고리의 다른 글
| [vegeta] 부하 테스트 (0) | 2023.11.14 |
|---|---|
| [Gunicorn]max_requests와 max_requests_jitter (0) | 2023.11.09 |
| [개발환경 구성] 모놀로식 아키텍처 (0) | 2023.07.04 |
| [mathplotlib] 한글 깨짐 (0) | 2023.06.12 |
| [Python] 이모지 제거 (0) | 2023.02.08 |