ML/Numpy
-
 [Numpy] argsort() 사용법 2023.01.10
[Numpy] argsort() 사용법 2023.01.10 -
 [Numpy, Scipy] np.array, toarray() 차이 2022.12.16
[Numpy, Scipy] np.array, toarray() 차이 2022.12.16 -
 [Numpy] 스칼라, 벡터, 행렬, 텐서 차이 2022.12.16
[Numpy] 스칼라, 벡터, 행렬, 텐서 차이 2022.12.16 -
 [Numpy] 넘파이 배열(np.array) 2022.11.09
[Numpy] 넘파이 배열(np.array) 2022.11.09
[Numpy] argsort() 사용법
import numpy as np
num = [6, 2, 8, 4, 1, 7]
num_arr = np.array(num)
sort_index = np.argsort(num_arr)
print(sort_index)[4 1 3 0 5 2]
argsort는 array를 오름차순으로 정렬한 후 해당 원소의 원래 인덱스를 출력한다.
아래 그림과 같다.

num_arr에서 원소에 해당하는 인덱스는 그림 왼쪽 아래에 나타난 index이다.
num_arr을 오름차순한다면 1, 2, 4, 6, 7, 8이 된다.
원래의 num_arr에서
원소 1의 본래 인덱스는 4이고 / 원소 2의 본래 인덱스는 1이고 ... / 원소 8의 본래 인덱스는 2이므로
[4 1 3 0 5 2] 를 출력하게 된다.
[::-1]을 붙이면 내림차순이 된다.
import numpy as np
num = [6, 2, 8, 4, 1, 7]
num_arr = np.array(num)
ascending_sort_index = np.argsort(num_arr)
descending_sort_index = np.argsort(num_arr)[::-1]
print('오름차순 : ', np.sort(num_arr))
print('인덱스 : ', ascending_sort_index)
print('\n내림차순 : ', np.sort(num_arr)[::-1])
print('인덱스 : ', descending_sort_index)
'ML > Numpy' 카테고리의 다른 글
| [Numpy, Scipy] np.array, toarray() 차이 (0) | 2022.12.16 |
|---|---|
| [Numpy] 스칼라, 벡터, 행렬, 텐서 차이 (0) | 2022.12.16 |
| [Numpy] 넘파이 배열(np.array) (0) | 2022.11.09 |
[Numpy, Scipy] np.array, toarray() 차이
from sklearn.feature_extraction.text import CountVectorizer
sent = ['안녕', '감사', '연말', '편지', '눈사람']
vectorizer = CountVectorizer()
bow_vec = vectorizer.fit_transform(sent)
print(type(bow_vec))
# <class 'scipy.sparse.csr.csr_matrix'>Bow를 테스트해보다가 문득 toarray()와 np.array()의 차이점이 궁금해졌다.
평소 array를 만들 때의 코드는 아래와 같다.
li = [[[1, 2, 3], [3, 4, 5]], [[6, 7, 8], [9, 10, 11]]]
arr = np.array(li)
np.array와 toarray()의 사용법을 보면 차이점을 알 수 있다.
- np.array(__array__ 메서드가 배열을 반환하는 객체 또는 (중첩된) 시퀀스)
- csr_matrix.toarray()
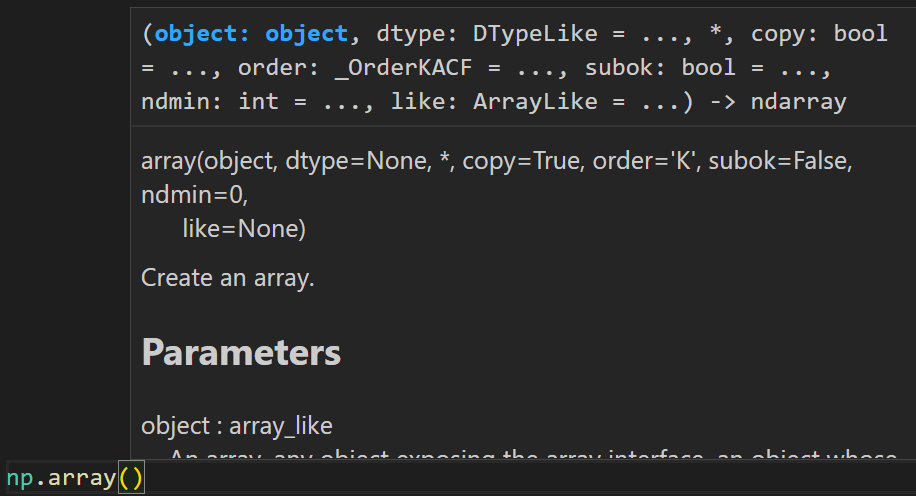
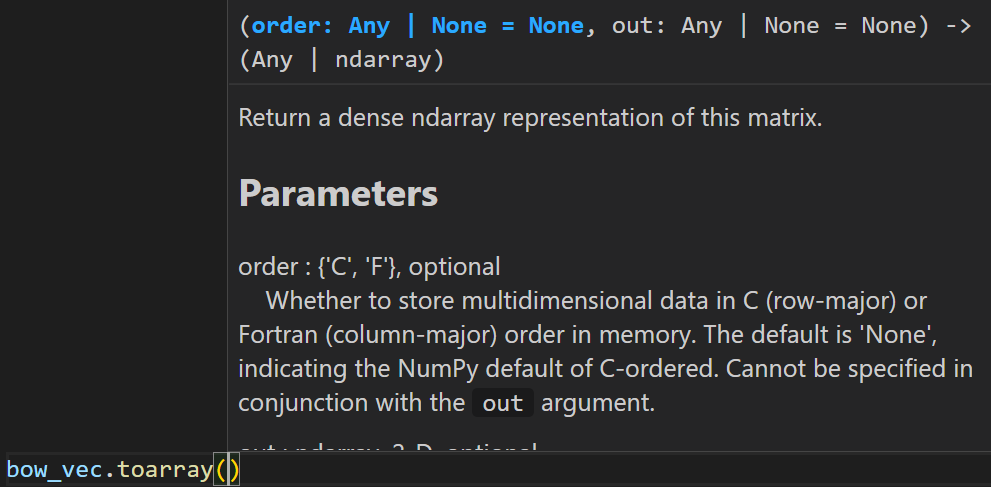
차이점이 뭘까라는 의문이 든 것 자체가 이상하다.
sort()와 sorted()의 차이점이라면 모를까..!!
array()는 numpy 라이브러리의 메서드이며,
toarray()는 scipy 라이브러리의 메서드이다.
궁금증이 생겼다면 numpy와 scipy 라이브러이의 차이점이 궁금했어야 했다..
(사용법에만 급급하지 말자..!)
해당 변수에 type을 출력해보면 <class 'numpy.ndarray'>와 <class 'scipy.sparse.csr.csr_matrix'>이다.
numpy.org와 scipy.org에서 각 메서드와 사용법을 찾아볼 수 있다.


두 메서드 모두 numpy.ndarray를 반환하지만 어떤 객체를 array로 변환할지의 차이다.
csr_matrix가 __array__메서드가 배열을 반환하는 객체 또는 시퀀스인지 확인하는 방법을 모르겠다..!!!!!
우선 np.array()에 csr_matrix를 넘겨봤다.
아래 코드에서 bow_vec의 type은 <class 'scipy.sparse.csr.csr_matrix'> 이다.
na = np.array(bow_vec)
ta = bow_vec.toarray()
print(type(na))
print('***** np.array(metrix) *****')
print(na)
print(type(ta))
print('***** metrix.toarray() *****')
print(ta)
값이 다르다.
배열은 반복가능하므로 각각을 for문을 실행해보자.
for i in na:
print(i)
iteration over a 0-d array 오류가 발생한다.
0-d array 는 0차원의 배열을 의미한다.
즉, 스칼라다.
배열을 반환하긴 하는데 결국 스칼라다..
Stackoverflow에도 numpy의 0d 배열이 스칼라로 간주되지 않는 이유를 묻는 질문이 있었고
이에 대한 답변엔 어렵게 생각하면 안된다. 정신건강에 좋지 않다는 답변과 수학적으로 같지만 다른 코드로 처리된다는 답이 있었다.
(해당글 : https://stackoverflow.com/questions/773030/why-are-0d-arrays-in-numpy-not-considered-scalar)
csr_matrix.toarray()의 반환값을 반복해보자.
for i in ta:
print(i)
역시 잘 출력된다.
'ML > Numpy' 카테고리의 다른 글
| [Numpy] argsort() 사용법 (0) | 2023.01.10 |
|---|---|
| [Numpy] 스칼라, 벡터, 행렬, 텐서 차이 (0) | 2022.12.16 |
| [Numpy] 넘파이 배열(np.array) (0) | 2022.11.09 |
[Numpy] 스칼라, 벡터, 행렬, 텐서 차이
import numpy as np스칼라 - 0D(demension, 차원) 텐서
크기만 갖고 있는 값
ex ) 1, 2, 3, ... , n
scalar = 3
zero_d_tenser = np.array(scalar)
print('값 : ', zero_d_tenser)
print('축(axis)의 개수 (= 차원) : ', zero_d_tenser.ndim)
print('크기 : ', zero_d_tenser.shape)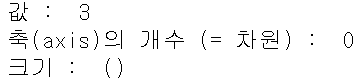
벡터 - 1D 텐서
크기와 방향을 갖는 1차원 값
(열,)
ex ) [ 1, 2, 3, ... , n ]
vec = [3, 6, 9]
one_d_tenser = np.array(vec)
print('값 : ', one_d_tenser)
print('축(axis)의 개수 (= 차원) : ', one_d_tenser.ndim)
print('크기 : ', one_d_tenser.shape)

위에 선언한 one_d_tenser는 3차원 벡터이자 1차원 텐서이다.
n차원 벡터 : 벡터 안 원소의 개수 (벡터에서의 차원)
n차원 텐서 : 축의 개수 (텐서에서의 차원)
행렬 - 2D 텐서
행과 열을 갖는 2차원 값
(행, 열)
ex ) [ [1, 2] , [3, 4], ... [n, m] ]
metrix= [[3], [6], [9]]
two_d_tenser = np.array(metrix)
print('값 : \n', two_d_tenser)
print('축(axis)의 개수 (= 차원) : ',two_d_tenser.ndim)
print('크기 : ', two_d_tenser.shape)
※ 주의 ※ 이전글 참고 : 넘파이 배열(np.array)
metrix= [[3], [6, 7], [9]]
two_d_tenser = np.array(metrix)
print('값 : \n', two_d_tenser)
print('축(axis)의 개수 (= 차원) : ',two_d_tenser.ndim)
print('크기 : ', two_d_tenser.shape)
텐서 - 3D 텐서
행과 열, 깊이를 갖는 3차원 값
(깊이, 행, 열)
ex ) [ [[1, 2]], [[3, 4]], ... , [[n,m] ]
tensor= [[[1, 2, 3]], [[3, 4, 5]]]
three_d_tenser = np.array(tensor)
print('값 : \n', three_d_tenser)
print('축(axis)의 개수 (= 차원) : ',three_d_tenser.ndim)
print('크기 : ', three_d_tenser.shape)
tensor= [[[1, 2, 3], [3, 4, 5]], [[6, 7, 8], [9, 10, 11]]]
three_d_tenser = np.array(tensor)
print('값 : \n', three_d_tenser)
print('축(axis)의 개수 (= 차원) : ',three_d_tenser.ndim)
print('크기 : ', three_d_tenser.shape)
'ML > Numpy' 카테고리의 다른 글
| [Numpy] argsort() 사용법 (0) | 2023.01.10 |
|---|---|
| [Numpy, Scipy] np.array, toarray() 차이 (0) | 2022.12.16 |
| [Numpy] 넘파이 배열(np.array) (0) | 2022.11.09 |
[Numpy] 넘파이 배열(np.array)
배열(array)과 list 차이점
- 배열은 모든 원소가 같은 자료형이어야 함
- 배열 내 원소 개수가 모두 같아야 함
- 사용가능한 메소드

Numpy는 수치해석용 파이썬 패키지
다차원 배열 자료구조 클래스인 ndarray를 지원
벡터와 행렬을 사용하는 선형대수 계산에 주로 사용
리스트 내 원소가 같을 경우
a = np.array([[1, 2], [3, 4]])
print(a)
print(a.shape)# 결과
# a
[[1 2]
[3 4]]
# a.shape
(2, 2)
>> 2X2 의 2차원 array가 생성
리스트 내 원소가 다를 경우
b = np.array([[1, 2, 3], [4, 5]])
print(b)
print(b.shape)# 결과
# b
[list([1, 2, 3]) list([4, 5])]
# b.shape
(2,)
>> 각 리스트의 원소 개수가 달라 1차원 array가 생성
* list()는 array()와 헷갈릴까봐 표시?? [ [ ], [ ], ... , [ ] ] 로 보면 됨 (shape찍어보면 (2,)이기 때문)!
'ML > Numpy' 카테고리의 다른 글
| [Numpy] argsort() 사용법 (0) | 2023.01.10 |
|---|---|
| [Numpy, Scipy] np.array, toarray() 차이 (0) | 2022.12.16 |
| [Numpy] 스칼라, 벡터, 행렬, 텐서 차이 (0) | 2022.12.16 |