Python/파이썬 중급
-
 [Python] 코루틴 사용법 1 2024.01.26
[Python] 코루틴 사용법 1 2024.01.26 -
[Python] 어노테이션(annotation), typing 2023.04.10
-
 [Python] 코루틴 (Coroutine) 2023.02.16
[Python] 코루틴 (Coroutine) 2023.02.16 -
 [Python] 이터레이터(iterator), 제너레이터(generator) 2022.12.14
[Python] 이터레이터(iterator), 제너레이터(generator) 2022.12.14 -
 [Python] setdefault 함수 2022.12.11
[Python] setdefault 함수 2022.12.11 -
 [Python] sorted, sort 함수 2022.12.11
[Python] sorted, sort 함수 2022.12.11 -
 [Python] mutable(가변 객체), immutable(불변 객체) 2022.12.08
[Python] mutable(가변 객체), immutable(불변 객체) 2022.12.08 -
 [Python] map, filter 함수 2022.12.07
[Python] map, filter 함수 2022.12.07
[Python] 코루틴 사용법
asyncio.run()
이 함수는 외부에서 호출되며,
코루틴을 실행하기 위한 새로운 이벤트 루프를 생성하고, 코루틴이 완료될 때까지 이벤트 루프를 실행한 후 종료
기본적으로 프로그램의 진입점에서 한 번 사용
asyncio.create_task()
이벤트 루프 내에서 비동기적으로 실행할 코루틴을 task로 스케쥴링
이렇게 생성된 task는 즉시 이벤트 루프에 의해 실행되며 task의 완료를 기다리지 않고 다음 줄의 코드가 실행됨
await
코루틴 실행을 일시 중단하고, 해당 코루틴이 완료될 때까지 현재 코루틴의 실행을 중지
완료되면, await 다음의 코드가 실행됨
비동기 작업이 완료될 때까지 기다려야 할 경우에 사용
ex) 특정 데이터를 받아와야 다음 단계의 코드를 실행할 수 있는 경우
await는 비동기 작업의 완료를 기다리지만, 전통적인 blocking 방식과는 다름
블록킹 방식에서는 작업이 완료될 때까지 프로그램의 실행히 완전히 멈춤
반면, 비동기 방식에서는 await으로 특정 작업의 완료를 기다리는 동안 이벤트 루프가 다른 비동기 작업을 수행할 수 있게 해줌
완료를 기다리지만 다른 작업을 수행할 수 있게 한다?
이해가 잘 안된다.
예시를 보자.
1. await을 만난 비동기 작업 A는 I/O 작업 등으로 인해 완료를 기다려야 한다.
2. 이벤트 루프는 작업 A가 완료될 때까지 대기하고 있을 동안, 다른 준비된 비동기 작업 B를 실행한다.
3. 작업 B도 await을 만나면, 이벤트 루프는 다시 다른 준비된 작업(ex: 작업 C)으로 전환할 수 있다.
4. 이 과정을 통해, 이벤트 루프는 실행 가능한 비동기 작업을 계속 찾아 실행하며, 각 작업의 대기 시간을 효율적으로 활용한다.
결국, await으로 인해 기다려야 하는 특정 작업이 있더라도, 프로그램 전체가 멈추는 것이 아니라,
가능한 다른 작업들을 계속해서 처리할 수 있다.
이것이 바로 비동기 프로그래밍이 제공하는 동시성의 이점이다!
import asyncio
import datetime
async def my_task(num, second):
start_time = datetime.datetime.now()
print(f"Task {num} 시작")
await asyncio.sleep(second) # second초 후에 작업이 완료됩니다.
end_time = datetime.datetime.now()
print(f"Task {num} 완료")
return end_time - start_time
async def main():
start_time = datetime.datetime.now()
# my_task를 태스크로 스케줄링합니다.
# 태스크는 즉시 이벤트 루프에 의해 실행되지만, main()의 흐름은 여기서 멈추지 않습니다.
task1 = asyncio.create_task(my_task(1, 2))
# 이 시점에서 main()의 다음 줄로 바로 넘어갑니다. 태스크의 완료를 기다리지 않습니다.
print("main()의 다음 코드 실행")
task2 = asyncio.create_task(my_task(2, 5))
# 그러나 여기서 await을 사용하여 태스크의 완료를 기다립니다.
duration1 = await task1
duration2 = await task2
end_time = datetime.datetime.now()
print(f"Task 1 소요 시간: {duration1}")
print(f"Task 2 소요 시간: {duration2}")
print(f"main 함수의 전체 실행 시간: {end_time - start_time}")
# 이벤트 루프를 시작하고 main() 코루틴을 실행합니다.
asyncio.run(main())
전체 실행 시간이 7초가 아닌 5초로 단축됐다.
asyncio.Future()
비동기 작업의 결과를 나타내는데 사용되는 객체
아직 완료되지 않은 작업을 추적하고, 해당 작업이 완료되면 결과를 저장, 이후 결과 조회 가능
* Future 객체의 주요 메서드 *
cancel() : Future의 작업 취소, 작업이 이미 완료되었거나 취소되었다면 효과 없음
cancelled() : Future의 작업이 취소되었는지 여부 반환
done() : Future의 작업이 완료되었는지 여부 반환
result() : Future의 결과 반환, Future가 아직 완료되지 않았다면, 호출자를 block
set_result() : Future의 결과를 설정, Future가 완료되었음을 알리며, result() 호출에 의해 반환될 값 설정
asyncio.gather()
주어진 코루틴이나 Future 객체들을 동시에 실행하고, 모든 결과를 하나의 리스트로 반환
gather로 실행 중인 코루틴이라 Future 객체들이 독립적을 실행되고,
서로의 완료를 기다리지는 않음
import asyncio
async def worker(future):
print('Worker: Starting work')
await asyncio.sleep(1)
print('Worker: Done with work')
future.set_result('Worker result')
async def boss(future):
print('Boss: Waiting for worker to finish')
result = await future
print(f'Boss: Received result: {result}')
async def main():
future = asyncio.Future()
await asyncio.gather(boss(future), worker(future))
asyncio.run(main())
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 어노테이션(annotation), typing (0) | 2023.04.10 |
|---|---|
| [Python] 코루틴 (Coroutine) (0) | 2023.02.16 |
| [Python] 이터레이터(iterator), 제너레이터(generator) (0) | 2022.12.14 |
| [Python] setdefault 함수 (0) | 2022.12.11 |
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
[Python] 어노테이션(annotation), typing
타입 어노테이션(type annotation)
타입에 대한 힌트 제공 (다른 type을 입력해도 에러가 발생하지 않음)
# 변수 선언
name:str = 'sso'
# 함수 매개변수, 반환값
def add(a: int, b: int) -> int:
return a + btyping 모듈
타입 체크 (다른 type을 입력하면 에러 발생)
from typing import List, Dict, Tuple, Set, Union, Final
# List
def add(nums:List[int]) -> int:
return sum(n for n in nums)
# Dict (key type, value type)
dic: Dict[str, int] = {'sso', '1'}
※ python 3.9이상부터는 typing 모듈 import없이 사용 가능
dic: dict[str, int] = {'sso', '1'}'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 코루틴 사용법 (1) | 2024.01.26 |
|---|---|
| [Python] 코루틴 (Coroutine) (0) | 2023.02.16 |
| [Python] 이터레이터(iterator), 제너레이터(generator) (0) | 2022.12.14 |
| [Python] setdefault 함수 (0) | 2022.12.11 |
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
[Python] 코루틴 (Coroutine)
코루틴을 공부할수록 헷갈렸던 개념들까지 정리하고자 한다.
🟡 동기 (synchronous)
- 요청을 보냈을 때 응답이 돌아와야 다음 동작 수행
- A 작업이 모두 끝날 때까지 B 작업은 대기
🟡 비동기 (asynchronous)
- 응답 상태와 상관없이 다음 동작 수행
- A 작업과 B 작업을 동시에 실행
- multiprocessing, multithreading, asyncio 라이브러리를 통해 구현 가능
🟡 동시성 (Concurrency)
- 동시에 작업을 수행하는 것이 아닌, 동시에 하는 것 처럼 느껴지게 하기 위한 시분할 처리
- 각 작업을 번갈아가며 실행 (A|B|A|B|A|B|A ...)
- 작업 시간은 (A : 5분 + B : 3분 = 8분)으로 단축 없이 동일하지만 사용자는 동시에 일어나는 것 처럼 보임
- 동시성에는 문맥 교환이 발생
- 코루틴, 싱글 코어에서 멀티 쓰레드로 구현 가능
↓문맥 교환 알아보기
문맥 교환(context switching) : 현재 CPU를 사용중인 프로세스의 CPU 제어권이 다른 프로세스로 이양되는 과정
현재 프로세스(A)는 CPU 사용시간이 끝나면 스케줄링 알고리즘에 의해 다음 프로세스(B)한테 CPU를 넘겨줘야 함
이 때 현재 프로세스(A)는 문맥을 자신의 PCB(Process Control Block, 프로세스 제어 블록)에 저장하게 되고 다음 프로세스(B)는 전에 저장했던 자신의 문맥을 PCB로부터 실제 하드웨어로 복원 시키는 과정이 필요함
각 프로세스는 프로세스 이미지를 가짐
프로세스 이미지 구성
- 프로세스 제어 블록(PCB)
- 프로세스의 모든 정보들이 들어있음 (스케줄링, 자원 할당, 인터럽트 처리 등)
- 텍스트 (코드, 명령어)
- 데이터
- 힙
- free area
- 스택
(위에 말이 맞다, 하지만 조금은 틀리다! 동시성 개념때문에 정말 헷갈렸다.. 밑에서 이어가도록 하자)
🟡 병렬성 (Parallelism)
- 정말로 동시에 여러 작업을 병렬로 수행
- CPU 코어(자원)당 한 개의 일을 함. 즉, 멀티 코어일 경우에 해당
- 작업 시간은 A : 5분, B : 3분일 경우 5분으로 시간 단축
- 멀티 코어에서 멀티 쓰레드로 구현 가능
🔸 쓰레드와 코루틴 차이점
쓰레드와 코루틴 모두 비동기 작업을 하기 위해 사용된다.
[ Thread A, B, C 가 있을 경우 ]
A를 수행하다가 B의 결과가 필요할 때, A는 블로킹이 되고 B로 문맥교환이 발생한다.
[ Coroutine A, B, C 가 있을 경우 ]
A를 진행하던 중 B가 실행되어도 실행중인 Thread를 정지하면서 기존 Thread에서 B를 실행한다.
따라서 Thread는 문맥교환의 비용이 발생하고
Coroutine은 문맥교환 없이 해당 루틴을 일시 중단해 기존 Thread 기법보다 비용이 적게 든다는 것이다.
일명 루틴이라고 불리는 Non-Blocking job을 정의한 뒤 멀티태스킹을 수행하는 것이 Coroutine이다.
Non-Blocking : 현재 작업을 수행중인 Main Thread를 중단(Blocking)하지 않고, 백그라운드에서 작업을 수행하여 현재 Thread를 종료하지 않도록 하는 비동기적 작업 수행
I/O bound와 CPU bound
앞서 동시성은 작업을 번갈아가며 진행하고 시간은 단축되지 않았다.
하지만 코루틴 예제를 찾아보다가 작업들의 실행이 겹치고 이로 인해 시간이 단축됨을 확인했다.
코루틴을 통해 동시성 프로그래밍을 할 수 있는데 어떻게 실행이 겹칠 수 있는지 개념적으로 헷갈렸다.
이는 CPU가 작업에 따라 어떻게 할당되는지를 알아야 한다.
컴퓨터가 수행하는 하나의 작업은 CPU 작업(CPU Bounded Task)과 I/O 작업(I/O Bounded Task)으로 구분된다.
🟡 I/O bound

작업 수행 시 CPU보다 I/O 작업이 많은 경우를 의미한다.
I/O bound 작업은 대부분 DB 데이터 송수신, 웹과 관련된 작업이다.
그림을 보면 실제 CPU 작업이 수행되는 시간은 파란색 뿐이다. 나머지 빨간색은 I/O 작업이 완료될 때까지 기다리는 시간이다. 따라서 이 시간동안 CPU는 쉬고 있다.
속도를 높이려면 CPU가 쉬는 시간에 일을 해야 한다.
🟡 CPU bound

작업 수행 시 I/O보다 CPU 작업이 많은 경우를 의미한다.
네트워크와 통신하거나 파일에 액세스 하지 않고 연산을 수행하는 프로그램과 같다.
프로그램의 속도에 영향을 끼치는 것이 네트워크나 파일 시스템이 아니라 오로지 CPU이다.
헷갈렸던 부분을 생각해보자.
예를 들어 A 작업을 코루틴에 등록해 실행하면
B 작업이 코루틴에 등록됐을 때 A 작업이 끝날 때까지 await이 발생해 대기하게 된다.
하지만 A 작업이 CPU를 사용하는 연산인 경우에만 파이썬의 작업이 할당된다. A 작업에서 네트워크 I/O나 파일 I/O와 같이 CPU 연산이 아닌 외부 입출력 작업을 할 때는 다른 작업이(B 작업)이 CPU에 할당될 수 있다.
따라서 이런 순간 동시에 작업이 처리가 되고 시간이 단축된다. (파이썬은 여전히 하나의 작업만 하는 것임)
I/O 작업이 일어나는 함수 앞에 await을 붙이면 효율적이다.
synchronous & asynchronous & block & non-block
코루틴을 적용하려면 알아야하는 개념이 있다.
앞선 동기 비동기를 다른 말로 정의해보자.
[ 호출되는 함수의 작업 완료 여부를 처리하는 주체의 차이 ]
🔸 동기 (synchronous)
- 호출된 함수의 수행 결과 및 종료를 호출한 함수가 처리함
- 호출하는 함수가 호출되는 함수의 작업 완료 후 리턴을 기다리거나 호출되는 함수로부터 바로 리턴을 받더라도 작업 완료 여부를 호출하는 함수가 계속 확인하며 신경씀
🔸 비동기 (asynchronous)
- 호출된 함수의 수행 결과 및 종료를 호출된 함수가 직접 신경 쓰고 처리함
- 호출되는 함수에게 callback을 전달해서, 호출되는 함수의 작업이 완료되면 호출되는 함수가 전달 받은 callback을 실행하고, 호출하는 함수는 작업 완료 여부를 신경쓰지 않음
[ 호출되는 함수가 바로 리턴하는지의 차이 ]
🟡 Block
호출된 함수가 자신이 할 일을 모두 마칠 때까지 제어권을 계속 갖고 호출한 함수에게 바로 돌려주지 않음
🟡 Non-Block
호출된 함수가 자신이 할 일을 마치지 않더라도 바로 제어권을 건네주어(return) 호출한 함수가 다른 일을 할 수 있음
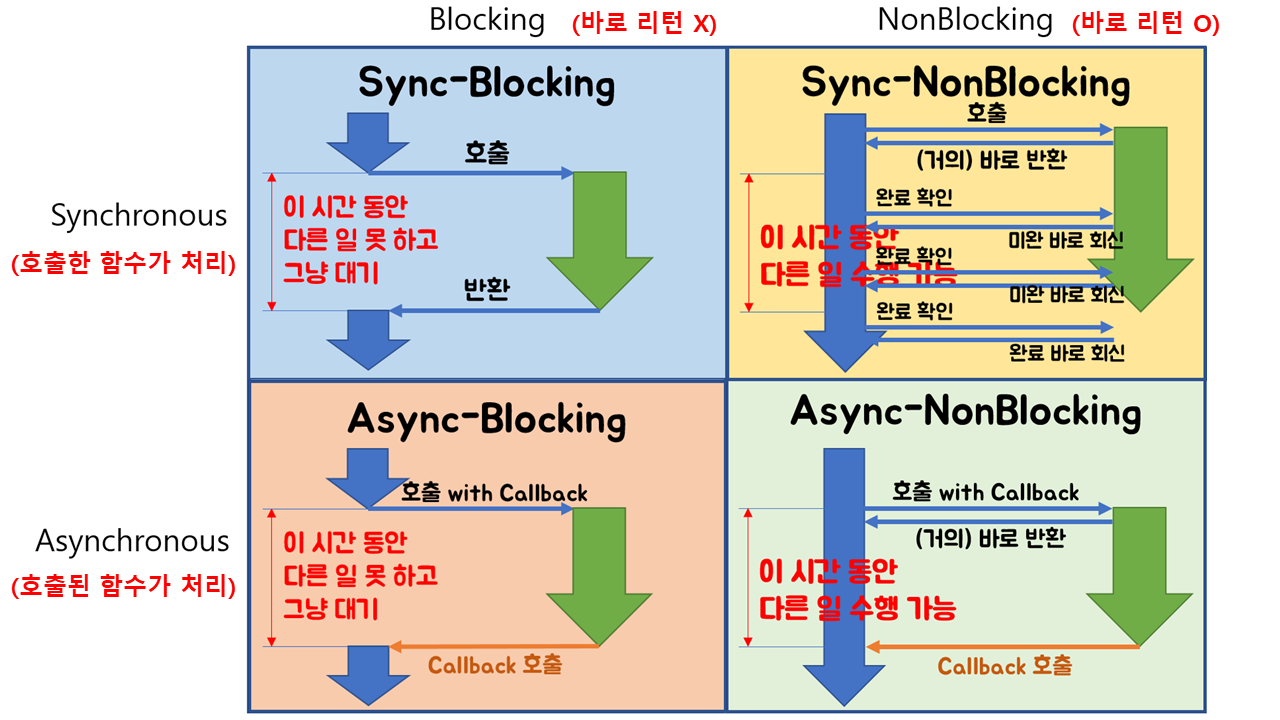
주의 : NonBlocking-Async 방식을 쓰는데 그 과정 중에 하나라도 Blocking으로 동작하는 일이 포함되어 있다면 의도하지 않게 Blocking-Async로 동작할 수 있음
↓더 알아보기
비동기 처리시 blocking되니 비동기 호출에서 async를 붙여 코루틴으로 구현하고
코루틴 객체가 CPU 연산을 하고 있을 때 해당 객체에 다시 접근하려 하면 blocking되어 있어 연산이 끝날 때까지 기다려야 된다.
따라서 파이썬에서 효율적으로 구현하기 위해서는 async로 구현된 객체가 blocking을 피할 수 있도록 multiprocessing을 할당해줘야 한다.
ex) 웹 프레임 워크의 worker(=프로세스)가 blocking되어 효율적으로 처리되지 못하는 코루틴 객체를 멀티 프로세싱으로 동작시켜 효율성을 올리는 것이다.
예시
예를 들어 웹페이지를 가져오는 코드를 짜야하는데
urlopen은 blocking함수라서 asyncio로 구현하는 효과가 크지 않음
방법 1
따라서 blocking함수를 멀티 쓰레드를 사용해 병렬로 실행시켜야 함
이 때 주의해야할 점이 있다.
파이썬에만 존재하는 GIL이라는게 있다.
GIL은 Python 인터프리터는 한 시점에 하나의 쓰레드에 의해서만 실행됨을 의미한다.
그러면 파이썬에서는 멀티 쓰레딩을 못하는 것으로 생각할 수 있지만 아니다.

위 그림처럼 여러 쓰레드가 병렬로 실행 될 수 없다는 의미일 뿐 멀티 쓰레딩은 가능하다.
이 역시 I/O bound에서 좋은 결과를 보인다.
CPU를 사용하지 않는 시간에 다른 쓰레드를 실행하기 때문이다.
따라서 CPU bound에서 병렬성 연산은 수행할 수 없으며,
sleep이나 위에 언급한 urlopen 등 외부 I/O 작업을 할 경우에 멀티 쓰레딩은 유용하다.
CPU bound 에서는 멀티 프로세싱을 이용해 GIL을 우회할 수 있다.
방법 2
멀티 스레딩을 사용하지 않고 asyncio + aiohttp를 사용하는 것이다.
aiohttp는 파이썬 request가 동기로 요청을 처리하기 때문에 이를 비동기로 http 요청을 처리하기 위한 라이브러리다.

멀티 스레딩, asyncio 차이점
https://superfastpython.com/threadpoolexecutor-vs-asyncio
ThreadPoolExecutor vs. AsyncIO in Python
You can use ThreadPoolExecutor for ad hoc IO-bound tasks and AsyncIO for asynchronous programming generally or for vast numbers of IO-bound tasks. In this tutorial, you will discover the difference…
superfastpython.com
더 알아볼 것
- 멀티 프로세싱
- subprocess
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 코루틴 사용법 (1) | 2024.01.26 |
|---|---|
| [Python] 어노테이션(annotation), typing (0) | 2023.04.10 |
| [Python] 이터레이터(iterator), 제너레이터(generator) (0) | 2022.12.14 |
| [Python] setdefault 함수 (0) | 2022.12.11 |
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
[Python] 이터레이터(iterator), 제너레이터(generator)
이터레이터 (iterator)
next 메소드를 통해 다음 값을 반환하는 객체
리스트, 튜플, string 등 for문을 사용해 하나씩 꺼내올 수 있다.
이러한 객체들을 iterable 객체라고 한다.
iterable 객체를 확인하는 방법은 아래와 같다.
li = ['가', '나', '다', '라', '마']
# __iter__가 있으므로 반복 가능하다
print(dir(li))
# 또는 hasttr 사용
print(hasattr(li, '__iter__'))
from collections import abc
# abc : abstract base class
# iterable 클래스를 상속 받았는지 확인
print(isinstance(li, abc.Iterable))

iterable 객체는 __iter__메서드를 갖고 있다.
itarable 객체는 iterator인지 확인해보자.
li = [1, 2, 3]
for i in li:
temp = i
next(li)리스트를 for문을 사용해 값을 한 개씩 꺼내올 순 있지만,
next 메소드를 사용하니 아래와 같은 오류가 발생한다.

리스트는 iterator가 아니다!
반복 가능한 객체인데 iterator로 만들 수 없을까?
답은 iter 함수를 사용하면 된다.
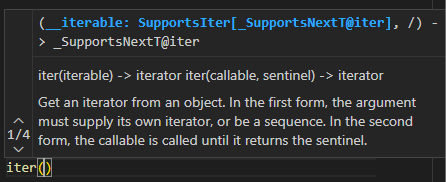
iter함수는 iterable 객체를 받아 iterator로 만들어 준다.
사용해보자.
li = [1, 2, 3]
li_iterator = iter(li)
print(type(li))
print(type(li_iterator))
print(next(li_iterator))
print(next(li_iterator))
print(next(li_iterator))
print(next(li_iterator))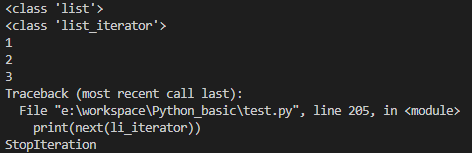
iter 함수로 리스트를 list_iterator 타입으로 변환했다.
dir로 이터레이터의 속성을 보면 __iter__와 __next__가 있다
print(dir(li_iterator))
따라서 위에서 언급한 iterator는 next 메소드를 사용해 다음 값을 반환할 수 있음을 확인할 수 있다.
모든 값을 반환한 후 next 메소드를 호출하니 StopIteration 예외가 발생한다.
iterator 또한 for문으로 반복가능하다.
for i in li_iterator:
print(i)
StopIteration 예외없이 출력된다!
iterable 객체의 실행순서는 다음과 같다.
iterable 객체 > __iter__() > iterator > __next__()
실제 for문도 iterable 객체가 iter()를 호출해서 iterable을 받아 next()를 호출하면서 실행된다.
(위에 for문에서는 iterable 객체가 아닌 iterator를 넘겨줬지만 이 또한 iter()를 호출하고 스스로를 반환한다.)
iter()는 __iter__ 메서드를 호출하고
next()는 __next__메서드를 호출한다.
__iter__메서드와 __next__메서드를 사용해 for문의 실행순서를 확인해보자. (iterator 구현)
class IterText:
def __init__(self, sentence):
self.sentence = sentence
self.idx = 0
def __iter__(self):
print('---iter() 동작---')
return self
def __next__(self):
if self.idx >= len(self.sentence):
raise StopIteration
print('---next() 동작---')
word = self.sentence[self.idx]
self.idx += 1
return word
it = IterText(['plz', 'study', 'continuously'])
for i in it:
print(i)
IterText 클래스에 리스트를 넘겨주면 __init__함수를 통해 sentence와 idx의 인스턴스 변수만 선언된다.
이후 for문을 실행시키면 it객체(iterable)가 __iter__함수를 실행한 후 __next__함수를 실행해 word를 하나씩 반환한다.
__iter__함수 없이 실행시키면 아래와 같은 오류가 발생한다.

위 코드에서 for문의 실행순서를 확인함과 동시에 클래스를 iterable하게 사용할 수 있다는 사실도 알 수 있다.
__iter__메서드와 __next__메서드만 구현하면 된다.
제너레이터(generator)
iterator를 생성해 주는 함수
위와 같이 간단한 예제는 메모리를 생각하지 않아도 된다.
하지만 데이터가 많은 리스트를 사용한다면, 메모리 부족이 생기기 쉽다.
제너레이터를 이용하면 모든 결과값을 한번에 메모리에 적재하지 않고 사용할 수 있다.
제너레이터 특징
- yield 키워드를 포함
- 한 번의 호출, 하나의 값을 반환
- 현재 상태 저장 후 정지
위 함수를 제너레이터로 구현해보자.
__iter__와 __next__ 메소드 없이 yield 키워드만 포함된 제너레이터 함수 작성만으로 가능하다.
class GeneratorText:
def __init__(self, sentence):
self.sentence = sentence
def gen(self):
print('---next() 동작---')
for word in self.sentence:
yield word
gt = GeneratorText(['plz', 'study', 'continuously'])
#제너레이터 객체 생성
gen_gt = gt.gen()
print(type(gen_gt))
#제너레이터 호출
word1 = next(gen_gt)
word2 = next(gen_gt)
word3 = next(gen_gt)
print(word1, word2, word3)
gen()은 yield 키워드를 포함하고 있으므로 제너레이터다.
print(dir(gen_gt))
제너레이터는 이터레이터를 생성해주는 함수라고 위에서 정의했다.
dir로 확인해보면 이터레이터가 갖고있는 __iter__와 __next__메소드를 갖고 있음을 확인할 수 있다.
제너레이터는 제너레이터 객체를 생성한 후 next(제너레이터 객체)를 통해 호출할 수 있다.
gt.gen()의 타입을 출력해보면 generator가 출력된다.
이를 사용하기 위해서는 next()를 사용하면 된다.
'---next() 동작---' 이 한 번만 출력된 것을 확인할 수 있다.
이는 처음 next(gen_gt)를 호출했을 때 출력되고 for문이 실행되면서 yield 키워드를 만나 word를 반환한 후 멈춰있기 때문이다.
다음 next()를 호출하면 for문이 다시 한 번 돌면서 word를 반환한 후 또 다시 멈춰있게 된다.
세 번째 next()를 호출하면 for문이 종료된다.
next()를 한 번 더 호출해보자.
word4 = next(gen_gt)
next 메소드를 호출하니 StopIteration 예외가 발생한다.
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 어노테이션(annotation), typing (0) | 2023.04.10 |
|---|---|
| [Python] 코루틴 (Coroutine) (0) | 2023.02.16 |
| [Python] setdefault 함수 (0) | 2022.12.11 |
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
| [Python] mutable(가변 객체), immutable(불변 객체) (0) | 2022.12.08 |
[Python] setdefault 함수
setdefault함수를 통해 dictionary에 default값을 삽입할 수 있다.
아래의 코드를 보자.
tu_to_dic =(
('name', '김'),
('name', '이'),
('name', '박'),
('age', 5),
('age', 3)
)
dic = {}
for k, v in tu_to_dic:
dic.setdefault(k, []).append(v)
print(dic)
이중 튜플을 선언한 후 이를 딕셔너리로 만들었다.
키값이 중복되어 value값이 마지막에 선언된 값으로 덮어써지는 것을 방지하기 위해 리스트를 통해 value를 받을 수 있다.
print(dic.setdefault('name'))
또한 setdefault함수를 사용해 key에 해당하는 value를 출력할 수 있다.
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 코루틴 (Coroutine) (0) | 2023.02.16 |
|---|---|
| [Python] 이터레이터(iterator), 제너레이터(generator) (0) | 2022.12.14 |
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
| [Python] mutable(가변 객체), immutable(불변 객체) (0) | 2022.12.08 |
| [Python] map, filter 함수 (0) | 2022.12.07 |
[Python] sorted, sort 함수
리스트를 정렬시켜주는 sorted와 sort 함수에 대해 알아보자.
sorted - 정렬 후 새로운 객체 반환
li_eng = ['car', 'banana', 'dog', 'animal']
li_kor = ['다람쥐', '가방', '나무']
li_num = [3, 1, 2]
print(sorted(li_eng))
print(sorted(li_kor))
print(sorted(li_num))
알파벳(a, b, c, ...), 한글(ㄱ, ㄴ, ㄷ, ...), 숫자(1, 2, 3, ...)를 기준으로 정렬되었다.

sorted()의 매개변수로 iterable(반복 가능한 객체)를 넘겨주었으며, 이 외에 key와 reverse 등의 매개변수를 넣을 수 있다.
reverse
reverse를 사용해 보자.
print(sorted(li_eng, reverse=True))
print(sorted(li_kor, reverse=True))
print(sorted(li_num, reverse=True))
reverse의 default 값은 False이다. True의 결과값은 앞선 결과의 반대로 정렬된다.
key
li_kor = ['날다람쥐', '까마귀', '참새']
print(sorted(li_kor, key=lambda x:x[-1]))
print(sorted(li_kor, key=len))
key를 통해 len을 기준으로, lambda함수에서 정의한 기준 등으로 정렬의 기준을 정할 수 있다.
lambda x:x[-1]의 결과로 마지막 글자를 기준으로 정렬한 값이 출력된다.
정렬 후 새로운 객체 반환
print(id(li_kor))
print(id(sorted(li_kor, key=len)))
sorted 함수는 정렬 후 새로운 객체를 반환한다.
정렬 전과 후의 id값을 확인해보면 다르다.
sort - 원본 객체 직접 변경
li_num = [53, 271, 2]
print(li_num)
print(li_num.sort())
print(li_num)
원본 객체 직접 변경
sort함수는 sorted함수와 다르게 원본 객체를 직접 변경한다.
따라서 리스트.sort()의 형식으로 사용한다.
여기서 알아둬야 할 점은 sort()의 반환값은 None이다.
id값으로 정렬 전 리스트와 정렬 후 리스트를 출력해보면 직접 변경되었음을 확인할 수 있다.
print(id(li_num))
print(li_num.sort())
print(id(li_num))
sort함수는 sorted와 마찬가지로 key와 reverse 매개변수를 넣어 사용할 수 있다.
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] 이터레이터(iterator), 제너레이터(generator) (0) | 2022.12.14 |
|---|---|
| [Python] setdefault 함수 (0) | 2022.12.11 |
| [Python] mutable(가변 객체), immutable(불변 객체) (0) | 2022.12.08 |
| [Python] map, filter 함수 (0) | 2022.12.07 |
| [Python] MappingProxyType (0) | 2022.12.07 |
[Python] mutable(가변 객체), immutable(불변 객체)
파이썬의 mutable, immutable 객체를 정확히 알고 가자.
mutable
생성 후 상태 변경 가능(가변)한 객체
객체들의 값이 같은 경우 각각 다른 id 값(변수의 메모리 주소값)을 가짐
한 객체의 상태 변경 전과 후는 같은 id 값(변수의 메모리 주소값)을 가짐
- list
- set
- dict
우선 생성 후 상태 변경 가능의 의미는 아래 코드를 보자.
li = [1, 2, 3]
li[0] = 3
print(li) # [3, 2, 3]li라는 list를 생성 후 0번째 인덱스의 값을 변경할 수 있다.
1. 객체들의 값이 같은 경우 각각 다른 id 값(변수의 메모리 주소값)을 가짐
li_1 = ['a', 'b', 'c']
li_2 = ['a', 'b', 'c']
li_3 = ['a', 'b', 'c']
print(id(li_1), id(li_2), id(li_3))
# 2501789136768 2501791190336 2501791159936li_1, li_2, li_3의 id값은 모두 다르다.
이는 세 개의 변수가 모두 다른 주소 값을 참조하고 있다는 말이다.
2. 한 객체의 상태 변경 전과 후는 같은 id 값(변수의 메모리 주소값)을 가짐
li = [1, 2, 3]
print(id(li))
# 1656961829056
li[0] = 3
print(id(li))
# 1656961829056
immutable
생성 후 상태 변경 불가(불변)한 객체
객체들의 값이 같은 경우 동일한 id 값(변수의 메모리 주소값)을 가짐
한 객체의 값 변경 전과 후는 다른 id 값(변수의 메모리 주소값)을 가짐
- int
- float
- bool
- str
- tuple
- frozenset
생성 후 상태 변경 불가능의 의미는 아래 코드를 보자.
s = '123'
s[0] = '3'
오류 메세지를 보면 아이템 할당을 지원하지 않는다고 한다.
s라는 string을 생성한 후 0번째 인덱스를 바꿀 수 없다.
1. 객체들의 값이 같은 경우 동일한 id 값(변수의 메모리 주소값)을 가짐
s_1 = 'abc'
s_2 = 'abc'
s_3 = 'abc'
print(id(s_1), id(s_2), id(s_3))
# 2501787757104 2501787757104 2501787757104s_1, s_2, s_3의 id값은 모두 같다.
이는 세 개의 변수가 모두 같은 주소 값을 참조하고 있다는 말이다.
2. 한 객체의 값 변경 전과 후는 다른 id 값(변수의 메모리 주소값)을 가짐
s = '123'
print(id(s))
# 3081990308208
s = '456'
print(id(s))
# 3081990308272위 1번에서 객체들의 값이 같을 경우 동일한 id값을 가진다고 했다.
값을 변경하여 객체들이 동일한 값을 갖게 한다면 같은 주소를 바라볼지 확인해보자.
2-1. list의 경우
s_1 = 'aBC'
s_2 = 'ABc'
print(id(s_1), id(s_2))
# 1480605368560 1480605368688
s_1 = s_1.upper()
s_2 = s_2.upper()
print(id(s_1), id(s_2))
# 1480605383920 1480605383792정답은 아니다!
s_1과 s_2 모두 upper()를 사용하여 'ABC'의 값을 동일하게 갖게 했지만 서로 다른 주소 값을 바라본다.
2-2. int의 경우
s_1 = 122
s_2 = 124
print(id(s_1), id(s_2))
# 2425745201296 2425745201360
s_1 += 1
s_2 -= 1
print(id(s_1), id(s_2))
# 2425745201328 2425745201328정답은 맞다! (값을 변경 후 동일한 값을 가진다면 동일한 주소값을 바라본다.)
mutable 안 immutable
mutable 안에 있는 immutable의 id 값을 확인해보자.
li_1 = ['a', {'s', 'e', 't'}]
li_2 = ['a', {'s', 'e', 't'}]
print(id(li_1), id(li_2))
# 1880871800576 1880871799680
print(id(li_1[0]), id(li_2[0]))
# 1880868556016 1880868556016
print(id(li_1[1]), id(li_2[1]))
# 1880871758752 1880871758080li_1과 li_2는 값이 같지만 mutable 객체이므로 id값이 서로 다르다.
각 list의 0번째 인덱스는 string 타입으로 immutable 객체다.
-> 동일한 값('a')을 가지므로 id값은 서로 같다.
각 list의 1번째 인덱스는 set 타입으로 mutable 객체다.
-> 동일한 값을 갖지만 mutable 객체이므로 id값이 서로 다르다.
앞서 말한 특성을 유지한다!
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] setdefault 함수 (0) | 2022.12.11 |
|---|---|
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
| [Python] map, filter 함수 (0) | 2022.12.07 |
| [Python] MappingProxyType (0) | 2022.12.07 |
| [Python] 네임드 튜플 (namedtuple) (0) | 2022.12.06 |
[Python] map, filter 함수
map 함수와 filter 함수에 대해 알아보자.
map

map 함수가 받는 인자를 보면 함수와 반복 가능한 객체이다.
map함수는 반복 가능한 객체를 받아 함수에 적용해준다.
예시 코드를 만들어보자.
li = [1, 2, 3]
a = map(lambda x : x+1, li)
print(type(a))
print(list(a))
간단한 예시를 위해 lambda함수를 사용했다.
재사용하는 함수를 따로 만든 후 적용해도 된다.
※ map함수의 출력 type은 class 이기 때문에 list로 감싼 후 출력해야 한다.
filter

filter 함수의 첫번째 인자는 함수 또는 None, 두번째 인자는 반복 가능한 객체이다.
map 함수와 비슷하게 반복 가능한 객체를 함수에 적용한다.
그 후 결과가 참일 경우 값을 반환한다.
첫번째 인자가 None일 경우, 반복 가능한 객체의 각 요소가 참인지는 판단한다.
예제 코드를 만들어보자.
li = ['가', 1, '나', 2]
def isStr(li):
if str(type(li)) == "<class 'str'>":
return True
return False
result = filter(isStr, li)
print(type(result))
print(list(result))
리스트 각 요소의 타입이 str이면 True를 반환하는 isStr함수를 만들었다.
filter의 두번째 인자가 반복 가능한 객체를 받기 때문에 isStr함수 내에서 for문을 통해 list의 각 요소를 꺼내오는 작업을 하지 않았다.
또한 map 함수와 마찬가지로
※ filter 함수의 출력 type은 class 이므로 list로 감싼 후 출력해야 한다.
filter + map
filter 함수의 두번째 인자로 map함수를 넣어보자.
li = [9.4, 9.8, 12.3]
result = list(filter(lambda x : x>=10, map(round, li)))
print(result)
filter함수의 첫번째 인자로 lambda 함수를 넣고, 두번째 인자로 map 함수를 넣었다.
map함수는 li의 각 요소를 반올림해주는 round 함수를 사용했다.
결과는 list로 반환했다.
'Python > 파이썬 중급' 카테고리의 다른 글
| [Python] sorted, sort 함수 (0) | 2022.12.11 |
|---|---|
| [Python] mutable(가변 객체), immutable(불변 객체) (0) | 2022.12.08 |
| [Python] MappingProxyType (0) | 2022.12.07 |
| [Python] 네임드 튜플 (namedtuple) (0) | 2022.12.06 |
| [Python] 매직 메소드 (0) | 2022.11.30 |